 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker discrimination in humans and machines: Effects of speaking style variability
Aug 08, 2020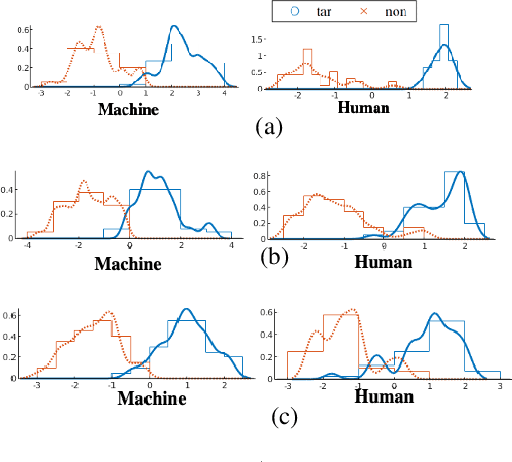
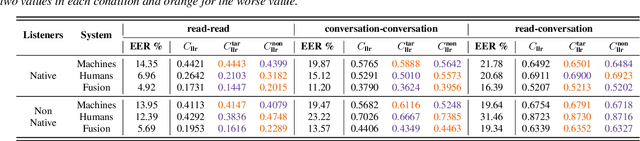
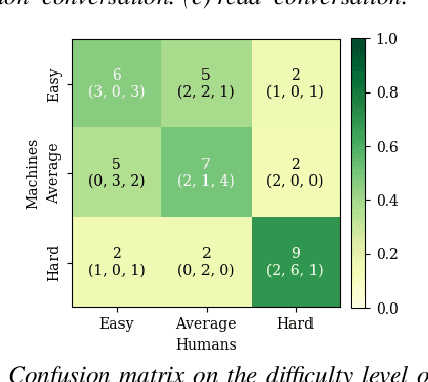
Does speaking style variation affect humans' ability to distinguish individuals from their voices? How do humans compare with automatic systems designed to discriminate between voices? In this paper, we attempt to answer these questions by comparing human and machine speaker discrimination performance for read speech versus casual conversations. Thirty listeners were asked to perform a same versus different speaker task. Their performance was compared to a state-of-the-art x-vector/PLDA-based automatic speaker verification system. Results showed that both humans and machines performed better with style-matched stimuli, and human performance was better when listeners were native speakers of American English. Native listeners performed better than machines in the style-matched conditions (EERs of 6.96% versus 14.35% for read speech, and 15.12% versus 19.87%, for conversations), but for style-mismatched conditions, there was no significant difference between native listeners and machines. In all conditions, fusing human responses with machine results showed improvements compared to each alone, suggesting that humans and machines have different approaches to speaker discrimination tasks. Differences in the approaches were further confirmed by examining results for individual speakers which showed that the perception of distinct and confused speakers differed between human listeners and machines.