 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarrier-enforced multi-objective optimization for direct point and sharp interval forecasting
Apr 20, 2026This paper proposes a multi-step probabilistic forecasting framework using a single neural-network based model to generate simultaneous point and interval forecasts. Our approach ensures non-crossing prediction intervals (PIs) through a model structure design that strictly satisfy a target coverage probability (PICP) while maximizing sharpness. Unlike existing methods that rely on manual weight tuning for scalarized loss functions, we treat point and PI forecasting as a multi-objective optimization problem, utilizing multi-gradient descent to adaptively select optimal weights. Key innovations include a new PI loss function based on an extended log-barrier with an adaptive hyperparameter to guarantee the coverage, a hybrid architecture featuring a shared temporal model with horizon-specific submodels, and a training strategy. The proposed loss is scale-independent and universally applicable; combined with our training algorithm, the framework eliminates trial-and-error hyperparameter tuning for balancing multiple objectives. Validated by an intra-day solar irradiance forecasting application, results demonstrate that our proposed loss consistently outperforms those in current literature by achieving target coverage with the narrowest PI widths. Furthermore, when compared against LSTM encoder-decoder and Transformer architectures--including those augmented with Chronos foundation models--our method remains highly competitive and can be seamlessly adapted to any deep learning structure.
Large width penalization for neural network-based prediction interval estimation
Nov 28, 2024



Forecasting accuracy in highly uncertain environments is challenging due to the stochastic nature of systems. Deterministic forecasting provides only point estimates and cannot capture potential outcomes. Therefore, probabilistic forecasting has gained significant attention due to its ability to quantify uncertainty, where one of the approaches is to express it as a prediction interval (PI), that explicitly shows upper and lower bounds of predictions associated with a confidence level. High-quality PI is characterized by a high PI coverage probability (PICP) and a narrow PI width. In many real-world applications, the PI width is generally used in risk management to prepare resources that improve reliability and effectively manage uncertainty. A wider PI width results in higher costs for backup resources as decision-making processes often focus on the worst-case scenarios arising with large PI widths under extreme conditions. This study aims to reduce the large PI width from the PI estimation method by proposing a new PI loss function that penalizes the average of the large PI widths more heavily. The proposed formulation is compatible with gradient-based algorithms, the standard approach to training neural networks (NNs), and integrating state-of-the-art NNs and existing deep learning techniques. Experiments with the synthetic dataset reveal that our formulation significantly reduces the large PI width while effectively maintaining the PICP to achieve the desired probability. The practical implementation of our proposed loss function is demonstrated in solar irradiance forecasting, highlighting its effectiveness in minimizing the large PI width in data with high uncertainty and showcasing its compatibility with more complex neural network models. Therefore, reducing large PI widths from our method can lead to significant cost savings by over-allocation of reserve resources.
Developing a Thailand solar irradiance map using Himawari-8 satellite imageries and deep learning models
Sep 21, 2024



This paper presents an online platform that shows Thailand's solar irradiance map every 30 minutes. It is available at https://www.cusolarforecast.com. The methodology for estimating global horizontal irradiance (GHI) across Thailand relies on cloud index extracted from Himawari-8 satellite imagery, Ineichen clear-sky model with locally-tuned Linke turbidity, and machine learning models. The methods take clear-sky irradiance, cloud index, re-analyzed GHI and temperature data from the MERRA-2 database, and date-time as inputs for GHI estimation models, including LightGBM, LSTM, Informer, and Transformer. These are benchmarked with the estimate from the SolCast service by evaluation of 15-minute ground GHI data from 53 ground stations over 1.5 years during 2022-2023. The results show that the four models have competitive performances and outperform the SolCast service. The best model is LightGBM, with an MAE of 78.58 W/sqm and RMSE of 118.97 W/sqm. Obtaining re-analyzed MERRA-2 data for Thailand is not economically feasible for deployment. When removing these features, the Informer model has a winning performance of 78.67 W/sqm in MAE. The obtained performance aligns with existing literature by taking the climate zone and time granularity of data into consideration. As the map shows an estimate of GHI over 93,000 grids with a frequent update, the paper also describes a computational framework for displaying the entire map. It tests the runtime performance of deep learning models in the GHI estimation process.
Joint learning of multiple Granger causal networks via non-convex regularizations: Inference of group-level brain connectivity
May 22, 2021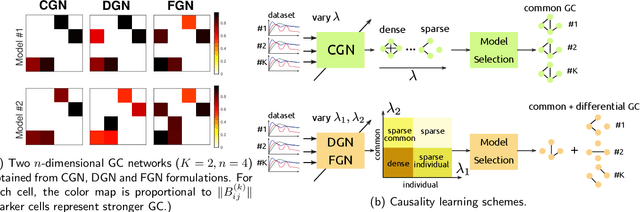

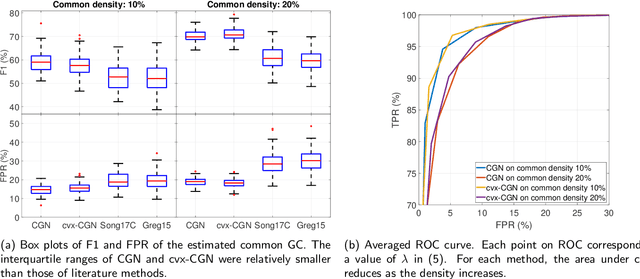
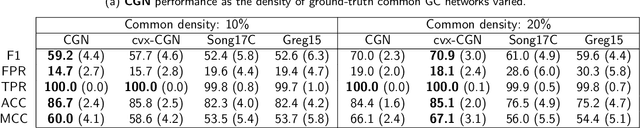
This paper considers joint learning of multiple sparse Granger graphical models to discover underlying common and differential Granger causality (GC) structures across multiple time series. This can be applied to drawing group-level brain connectivity inferences from a homogeneous group of subjects or discovering network differences among groups of signals collected under heterogeneous conditions. By recognizing that the GC of a single multivariate time series can be characterized by common zeros of vector autoregressive (VAR) lag coefficients, a group sparse prior is included in joint regularized least-squares estimations of multiple VAR models. Group-norm regularizations based on group- and fused-lasso penalties encourage a decomposition of multiple networks into a common GC structure, with other remaining parts defined in individual-specific networks. Prior information about sparseness and sparsity patterns of desired GC networks are incorporated as relative weights, while a non-convex group norm in the penalty is proposed to enhance the accuracy of network estimation in low-sample settings. Extensive numerical results on simulations illustrated our method's improvements over existing sparse estimation approaches on GC network sparsity recovery. Our methods were also applied to available resting-state fMRI time series from the ADHD-200 data sets to learn the differences of causality mechanisms, called effective brain connectivity, between adolescents with ADHD and typically developing children. Our analysis revealed that parts of the causality differences between the two groups often resided in the orbitofrontal region and areas associated with the limbic system, which agreed with clinical findings and data-driven results in previous studies.