 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE: Finding Sparse and Flat Minima to Improve Pruning
Jun 07, 2025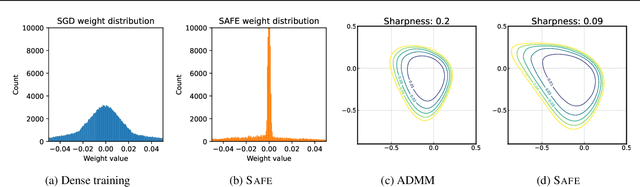
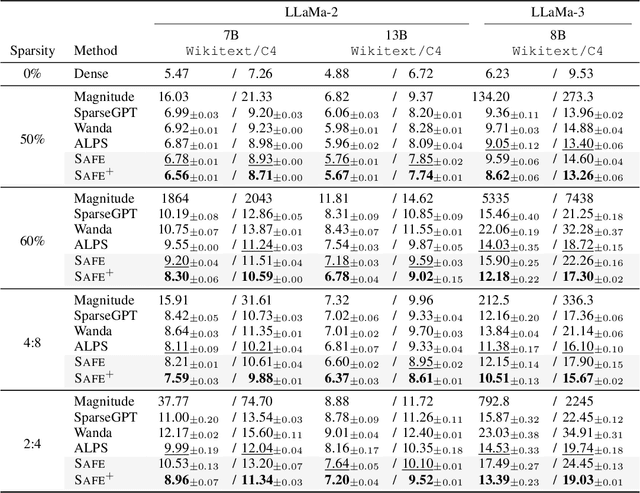
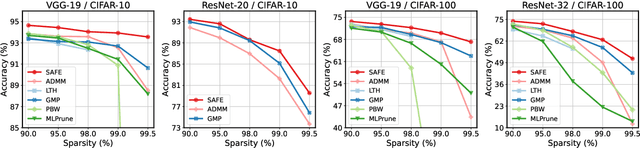

Sparsifying neural networks often suffers from seemingly inevitable performance degradation, and it remains challenging to restore the original performance despite much recent progress. Motivated by recent studies in robust optimization, we aim to tackle this problem by finding subnetworks that are both sparse and flat at the same time. Specifically, we formulate pruning as a sparsity-constrained optimization problem where flatness is encouraged as an objective. We solve it explicitly via an augmented Lagrange dual approach and extend it further by proposing a generalized projection operation, resulting in novel pruning methods called SAFE and its extension, SAFE$^+$. Extensive evaluations on standard image classification and language modeling tasks reveal that SAFE consistently yields sparse networks with improved generalization performance, which compares competitively to well-established baselines. In addition, SAFE demonstrates resilience to noisy data, making it well-suited for real-world conditions.
SASSHA: Sharpness-aware Adaptive Second-order Optimization with Stable Hessian Approximation
Feb 25, 2025



Approximate second-order optimization methods often exhibit poorer generalization compared to first-order approaches. In this work, we look into this issue through the lens of the loss landscape and find that existing second-order methods tend to converge to sharper minima compared to SGD. In response, we propose Sassha, a novel second-order method designed to enhance generalization by explicitly reducing sharpness of the solution, while stabilizing the computation of approximate Hessians along the optimization trajectory. In fact, this sharpness minimization scheme is crafted also to accommodate lazy Hessian updates, so as to secure efficiency besides flatness. To validate its effectiveness, we conduct a wide range of standard deep learning experiments where Sassha demonstrates its outstanding generalization performance that is comparable to, and mostly better than, other methods. We provide a comprehensive set of analyses including convergence, robustness, stability, efficiency, and cost.
FedFwd: Federated Learning without Backpropagation
Sep 03, 2023In federated learning (FL), clients with limited resources can disrupt the training efficiency. A potential solution to this problem is to leverage a new learning procedure that does not rely on backpropagation (BP). We present a novel approach to FL called FedFwd that employs a recent BP-free method by Hinton (2022), namely the Forward Forward algorithm, in the local training process. FedFwd can reduce a significant amount of computations for updating parameters by performing layer-wise local updates, and therefore, there is no need to store all intermediate activation values during training. We conduct various experiments to evaluate FedFwd on standard datasets including MNIST and CIFAR-10, and show that it works competitively to other BP-dependent FL methods.