 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteLMGuard: Seamless and Lightweight On-Device Prompt Filtering for Safeguarding Small Language Models against Quantization-induced Risks and Vulnerabilities
May 08, 2025The growing adoption of Large Language Models (LLMs) has influenced the development of their lighter counterparts-Small Language Models (SLMs)-to enable on-device deployment across smartphones and edge devices. These SLMs offer enhanced privacy, reduced latency, server-free functionality, and improved user experience. However, due to resource constraints of on-device environment, SLMs undergo size optimization through compression techniques like quantization, which can inadvertently introduce fairness, ethical and privacy risks. Critically, quantized SLMs may respond to harmful queries directly, without requiring adversarial manipulation, raising significant safety and trust concerns. To address this, we propose LiteLMGuard (LLMG), an on-device prompt guard that provides real-time, prompt-level defense for quantized SLMs. Additionally, our prompt guard is designed to be model-agnostic such that it can be seamlessly integrated with any SLM, operating independently of underlying architectures. Our LLMG formalizes prompt filtering as a deep learning (DL)-based prompt answerability classification task, leveraging semantic understanding to determine whether a query should be answered by any SLM. Using our curated dataset, Answerable-or-Not, we trained and fine-tuned several DL models and selected ELECTRA as the candidate, with 97.75% answerability classification accuracy. Our safety effectiveness evaluations demonstrate that LLMG defends against over 87% of harmful prompts, including both direct instruction and jailbreak attack strategies. We further showcase its ability to mitigate the Open Knowledge Attacks, where compromised SLMs provide unsafe responses without adversarial prompting. In terms of prompt filtering effectiveness, LLMG achieves near state-of-the-art filtering accuracy of 94%, with an average latency of 135 ms, incurring negligible overhead for users.
When AI Defeats Password Deception! A Deep Learning Framework to Distinguish Passwords and Honeywords
Jul 24, 2024
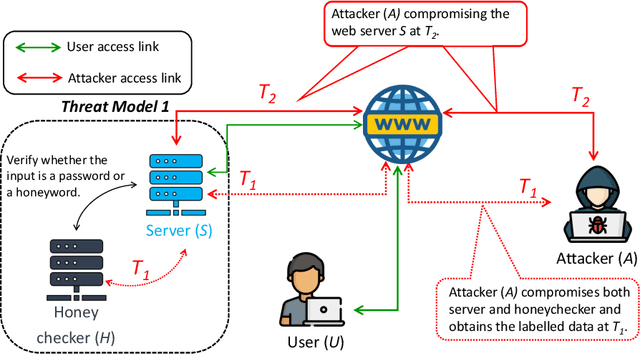


"Honeywords" have emerged as a promising defense mechanism for detecting data breaches and foiling offline dictionary attacks (ODA) by deceiving attackers with false passwords. In this paper, we propose PassFilter, a novel deep learning (DL) based attack framework, fundamental in its ability to identify passwords from a set of sweetwords associated with a user account, effectively challenging a variety of honeywords generation techniques (HGTs). The DL model in PassFilter is trained with a set of previously collected or adversarially generated passwords and honeywords, and carefully orchestrated to predict whether a sweetword is the password or a honeyword. Our model can compromise the security of state-of-the-art, heuristics-based, and representation learning-based HGTs proposed by Dionysiou et al. Specifically, our analysis with nine publicly available password datasets shows that PassFilter significantly outperforms the baseline random guessing success rate of 5%, achieving 6.10% to 52.78% on the 1st guessing attempt, considering 20 sweetwords per account. This success rate rapidly increases with additional login attempts before account lock-outs, often allowed on many real-world online services to maintain reasonable usability. For example, it ranges from 41.78% to 96.80% for five attempts, and from 72.87% to 99.00% for ten attempts, compared to 25% and 50% random guessing, respectively. We also examined PassFilter against general-purpose language models used for honeyword generation, like those proposed by Yu et al. These honeywords also proved vulnerable to our attack, with success rates of 14.19% for 1st guessing attempt, increasing to 30.23%, 41.70%, and 63.10% after 3rd, 5th, and 10th guessing attempts, respectively. Our findings demonstrate the effectiveness of DL model deployed in PassFilter in breaching state-of-the-art HGTs and compromising password security based on ODA.
Is On-Device AI Broken and Exploitable? Assessing the Trust and Ethics in Small Language Models
Jun 08, 2024



In this paper, we present a very first study to investigate trust and ethical implications of on-device artificial intelligence (AI), focusing on ''small'' language models (SLMs) amenable for personal devices like smartphones. While on-device SLMs promise enhanced privacy, reduced latency, and improved user experience compared to cloud-based services, we posit that they might also introduce significant challenges and vulnerabilities compared to on-server counterparts. As part of our trust assessment study, we conduct a systematic evaluation of the state-of-the-art on-devices SLMs, contrasted to their on-server counterparts, based on a well-established trustworthiness measurement framework. Our results show on-device SLMs to be (statistically) significantly less trustworthy, specifically demonstrating more stereotypical, unfair and privacy-breaching behavior. Informed by these findings, we then perform our ethics assessment study by inferring whether SLMs would provide responses to potentially unethical vanilla prompts, collated from prior jailbreaking and prompt engineering studies and other sources. Strikingly, the on-device SLMs did answer valid responses to these prompts, which ideally should be rejected. Even more seriously, the on-device SLMs responded with valid answers without any filters and without the need for any jailbreaking or prompt engineering. These responses can be abused for various harmful and unethical scenarios including: societal harm, illegal activities, hate, self-harm, exploitable phishing content and exploitable code, all of which indicates the high vulnerability and exploitability of these on-device SLMs. Overall, our findings highlight gaping vulnerabilities in state-of-the-art on-device AI which seem to stem from resource constraints faced by these models and which may make typical defenses fundamentally challenging to be deployed in these environments.
Breaking Indistinguishability with Transfer Learning: A First Look at SPECK32/64 Lightweight Block Ciphers
May 30, 2024



In this research, we introduce MIND-Crypt, a novel attack framework that uses deep learning (DL) and transfer learning (TL) to challenge the indistinguishability of block ciphers, specifically SPECK32/64 encryption algorithm in CBC mode (Cipher Block Chaining) against Known Plaintext Attacks (KPA). Our methodology includes training a DL model with ciphertexts of two messages encrypted using the same key. The selected messages have the same byte-length and differ by only one bit at the binary level. This DL model employs a residual network architecture. For the TL, we use the trained DL model as a feature extractor, and these features are then used to train a shallow machine learning, such as XGBoost. This dual strategy aims to distinguish ciphertexts of two encrypted messages, addressing traditional cryptanalysis challenges. Our findings demonstrate that the DL model achieves an accuracy of approximately 99% under consistent cryptographic conditions (Same Key or Rounds) with the SPECK32/64 cipher. However, performance degrades to random guessing levels (50%) when tested with ciphertext generated from different keys or different encryption rounds of SPECK32/64. To enhance the results, the DL model requires retraining with different keys or encryption rounds using larger datasets (10^7 samples). To overcome this limitation, we implement TL, achieving an accuracy of about 53% with just 10,000 samples, which is better than random guessing. Further training with 580,000 samples increases accuracy to nearly 99%, showing a substantial reduction in data requirements by over 94%. This shows that an attacker can utilize machine learning models to break indistinguishability by accessing pairs of plaintexts and their corresponding ciphertexts encrypted with the same key, without directly interacting with the communicating parties.