 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Persistent Homology Design Space for 3D Point Cloud Deep Learning
Apr 05, 2026Persistent Homology (PH) offers stable, multi-scale descriptors of intrinsic shape structure by capturing connected components, loops, and voids that persist across scales, providing invariants that complement purely geometric representations of 3D data. Yet, despite strong theoretical guarantees and increasing empirical adoption, its integration into deep learning for point clouds remains largely ad hoc and architecturally peripheral. In this work, we introduce a unified design space for Persistent-Homology driven learning in 3D point clouds (3DPHDL), formalizing the interplay between complex construction, filtration strategy, persistence representation, neural backbone, and prediction task. Beyond the canonical pipeline of diagram computation and vectorization, we identify six principled injection points through which topology can act as a structural inductive bias reshaping sampling, neighborhood graphs, optimization dynamics, self-supervision, output calibration, and even internal network regularization. We instantiate this framework through a controlled empirical study on ModelNet40 classification and ShapeNetPart segmentation, systematically augmenting representative backbones (PointNet, DGCNN, and Point Transformer) with persistence diagrams, images, and landscapes, and analyzing their impact on accuracy, robustness to noise and sampling variation, and computational scalability. Our results demonstrate consistent improvements in topology-sensitive discrimination and part consistency, while revealing meaningful trade-offs between representational expressiveness and combinatorial complexity. By viewing persistent homology not merely as an auxiliary feature but as a structured component within the learning pipeline, this work provides a systematic framework for incorporating topological reasoning into 3D point cloud learning.
Learning Significant Persistent Homology Features for 3D Shape Understanding
Feb 15, 2026Geometry and topology constitute complementary descriptors of three-dimensional shape, yet existing benchmark datasets primarily capture geometric information while neglecting topological structure. This work addresses this limitation by introducing topologically-enriched versions of ModelNet40 and ShapeNet, where each point cloud is augmented with its corresponding persistent homology features. These benchmarks with the topological signatures establish a foundation for unified geometry-topology learning and enable systematic evaluation of topology-aware deep learning architectures for 3D shape analysis. Building on this foundation, we propose a deep learning-based significant persistent point selection method, \textit{TopoGAT}, that learns to identify the most informative topological features directly from input data and the corresponding topological signatures, circumventing the limitations of hand-crafted statistical selection criteria. A comparative study verifies the superiority of the proposed method over traditional statistical approaches in terms of stability and discriminative power. Integrating the selected significant persistent points into standard point cloud classification and part-segmentation pipelines yields improvements in both classification accuracy and segmentation metrics. The presented topologically-enriched datasets, coupled with our learnable significant feature selection approach, enable the broader integration of persistent homology into the practical deep learning workflows for 3D point cloud analysis.
DepGAN: Leveraging Depth Maps for Handling Occlusions and Transparency in Image Composition
Jul 16, 2024

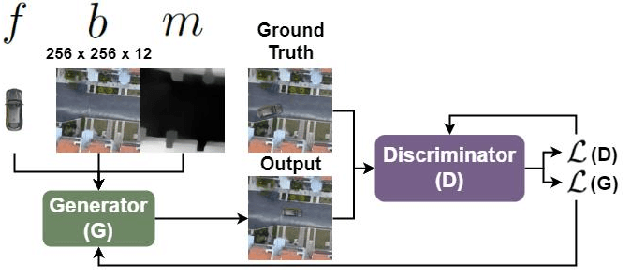

Image composition is a complex task which requires a lot of information about the scene for an accurate and realistic composition, such as perspective, lighting, shadows, occlusions, and object interactions. Previous methods have predominantly used 2D information for image composition, neglecting the potentials of 3D spatial information. In this work, we propose DepGAN, a Generative Adversarial Network that utilizes depth maps and alpha channels to rectify inaccurate occlusions and enhance transparency effects in image composition. Central to our network is a novel loss function called Depth Aware Loss which quantifies the pixel wise depth difference to accurately delineate occlusion boundaries while compositing objects at different depth levels. Furthermore, we enhance our network's learning process by utilizing opacity data, enabling it to effectively manage compositions involving transparent and semi-transparent objects. We tested our model against state-of-the-art image composition GANs on benchmark (both real and synthetic) datasets. The results reveal that DepGAN significantly outperforms existing methods in terms of accuracy of object placement semantics, transparency and occlusion handling, both visually and quantitatively. Our code is available at https://amrtsg.github.io/DepGAN/.
Point-JEPA: A Joint Embedding Predictive Architecture for Self-Supervised Learning on Point Cloud
Apr 25, 2024Recent advancements in self-supervised learning in the point cloud domain have demonstrated significant potential. However, these methods often suffer from drawbacks, including lengthy pre-training time, the necessity of reconstruction in the input space, or the necessity of additional modalities. In order to address these issues, we introduce Point-JEPA, a joint embedding predictive architecture designed specifically for point cloud data. To this end, we introduce a sequencer that orders point cloud tokens to efficiently compute and utilize tokens proximity based on their indices during target and context selection. The sequencer also allows shared computations of the tokens proximity between context and target selection, further improving the efficiency. Experimentally, our method achieves competitive results with state-of-the-art methods while avoiding the reconstruction in the input space or additional modality.