 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Automatic Generation and Simplification of Children's Stories
Oct 27, 2023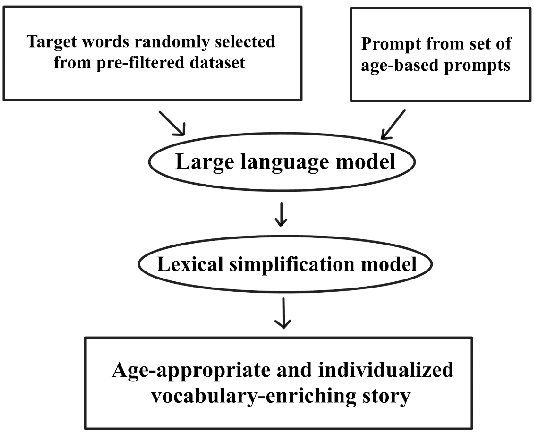

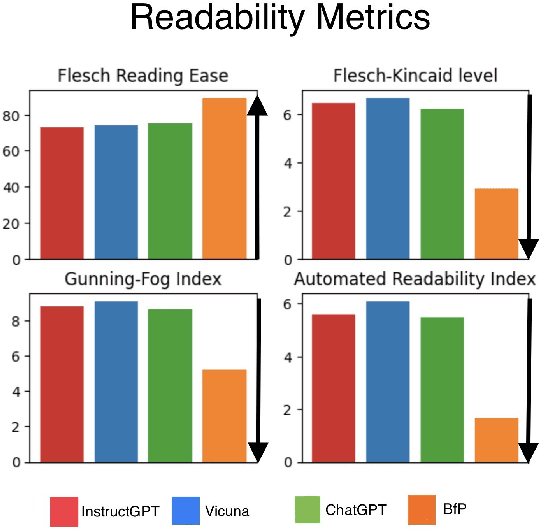

With recent advances in large language models (LLMs), the concept of automatically generating children's educational materials has become increasingly realistic. Working toward the goal of age-appropriate simplicity in generated educational texts, we first examine the ability of several popular LLMs to generate stories with properly adjusted lexical and readability levels. We find that, in spite of the growing capabilities of LLMs, they do not yet possess the ability to limit their vocabulary to levels appropriate for younger age groups. As a second experiment, we explore the ability of state-of-the-art lexical simplification models to generalize to the domain of children's stories and, thus, create an efficient pipeline for their automatic generation. In order to test these models, we develop a dataset of child-directed lexical simplification instances, with examples taken from the LLM-generated stories in our first experiment. We find that, while the strongest-performing current lexical simplification models do not perform as well on material designed for children due to their reliance on large language models behind the scenes, some models that still achieve fairly strong results on general data can mimic or even improve their performance on children-directed data with proper fine-tuning, which we conduct using our newly created child-directed simplification dataset.