 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Feature Vectors from Phonetic Transcriptions in Cross-Linguistic Data Formats
May 07, 2024



When comparing speech sounds across languages, scholars often make use of feature representations of individual sounds in order to determine fine-grained sound similarities. Although binary feature systems for large numbers of speech sounds have been proposed, large-scale computational applications often face the challenges that the proposed feature systems -- even if they list features for several thousand sounds -- only cover a smaller part of the numerous speech sounds reflected in actual cross-linguistic data. In order to address the problem of missing data for attested speech sounds, we propose a new approach that can create binary feature vectors dynamically for all sounds that can be represented in the the standardized version of the International Phonetic Alphabet proposed by the Cross-Linguistic Transcription Systems (CLTS) reference catalog. Since CLTS is actively used in large data collections, covering more than 2,000 distinct language varieties, our procedure for the generation of binary feature vectors provides immediate access to a very large collection of multilingual wordlists. Testing our feature system in different ways on different datasets proves that the system is not only useful to provide a straightforward means to compare the similarity of speech sounds, but also illustrates its potential to be used in future cross-linguistic machine learning applications.
A Computational Model for the Assessment of Mutual Intelligibility Among Closely Related Languages
Feb 05, 2024

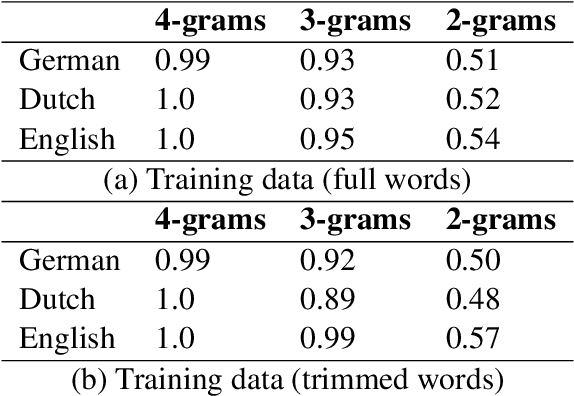

Closely related languages show linguistic similarities that allow speakers of one language to understand speakers of another language without having actively learned it. Mutual intelligibility varies in degree and is typically tested in psycholinguistic experiments. To study mutual intelligibility computationally, we propose a computer-assisted method using the Linear Discriminative Learner, a computational model developed to approximate the cognitive processes by which humans learn languages, which we expand with multilingual semantic vectors and multilingual sound classes. We test the model on cognate data from German, Dutch, and English, three closely related Germanic languages. We find that our model's comprehension accuracy depends on 1) the automatic trimming of inflections and 2) the language pair for which comprehension is tested. Our multilingual modelling approach does not only offer new methodological findings for automatic testing of mutual intelligibility across languages but also extends the use of Linear Discriminative Learning to multilingual settings.