 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Stage Deep Representation Learning-Based Speech Enhancement Method Using Variational Autoencoder and Adversarial Training
Nov 16, 2022This paper focuses on leveraging deep representation learning (DRL) for speech enhancement (SE). In general, the performance of the deep neural network (DNN) is heavily dependent on the learning of data representation. However, the DRL's importance is often ignored in many DNN-based SE algorithms. To obtain a higher quality enhanced speech, we propose a two-stage DRL-based SE method through adversarial training. In the first stage, we disentangle different latent variables because disentangled representations can help DNN generate a better enhanced speech. Specifically, we use the $\beta$-variational autoencoder (VAE) algorithm to obtain the speech and noise posterior estimations and related representations from the observed signal. However, since the posteriors and representations are intractable and we can only apply a conditional assumption to estimate them, it is difficult to ensure that these estimations are always pretty accurate, which may potentially degrade the final accuracy of the signal estimation. To further improve the quality of enhanced speech, in the second stage, we introduce adversarial training to reduce the effect of the inaccurate posterior towards signal reconstruction and improve the signal estimation accuracy, making our algorithm more robust for the potentially inaccurate posterior estimations. As a result, better SE performance can be achieved. The experimental results indicate that the proposed strategy can help similar DNN-based SE algorithms achieve higher short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), and scale-invariant signal-to-distortion ratio (SI-SDR) scores. Moreover, the proposed algorithm can also outperform recent competitive SE algorithms.
A deep representation learning speech enhancement method using $β$-VAE
May 11, 2022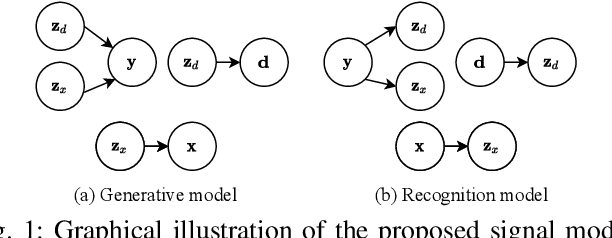
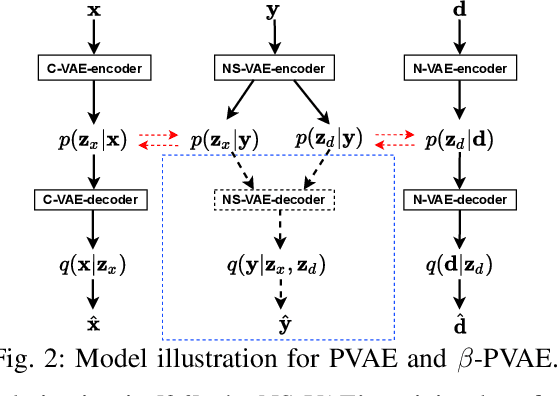
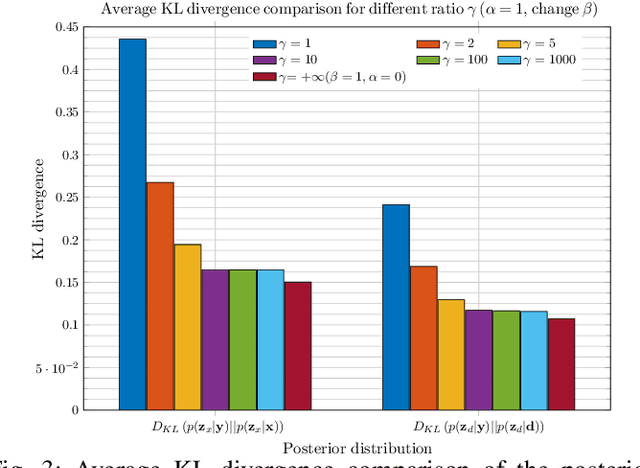
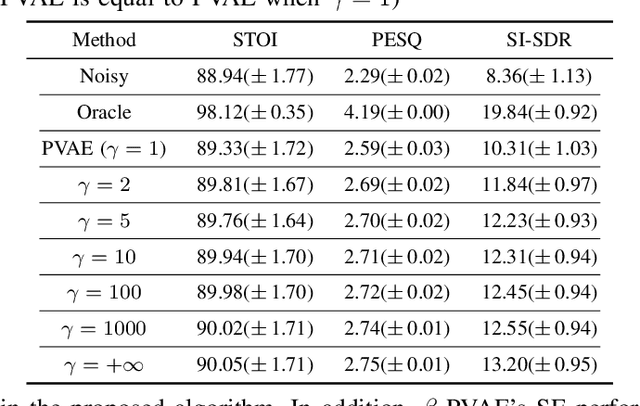
In previous work, we proposed a variational autoencoder-based (VAE) Bayesian permutation training speech enhancement (SE) method (PVAE) which indicated that the SE performance of the traditional deep neural network-based (DNN) method could be improved by deep representation learning (DRL). Based on our previous work, we in this paper propose to use $\beta$-VAE to further improve PVAE's ability of representation learning. More specifically, our $\beta$-VAE can improve PVAE's capacity of disentangling different latent variables from the observed signal without the trade-off problem between disentanglement and signal reconstruction. This trade-off problem widely exists in previous $\beta$-VAE algorithms. Unlike the previous $\beta$-VAE algorithms, the proposed $\beta$-VAE strategy can also be used to optimize the DNN's structure. This means that the proposed method can not only improve PVAE's SE performance but also reduce the number of PVAE training parameters. The experimental results show that the proposed method can acquire better speech and noise latent representation than PVAE. Meanwhile, it also obtains a higher scale-invariant signal-to-distortion ratio, speech quality, and speech intelligibility.
A Bayesian Permutation training deep representation learning method for speech enhancement with variational autoencoder
Jan 24, 2022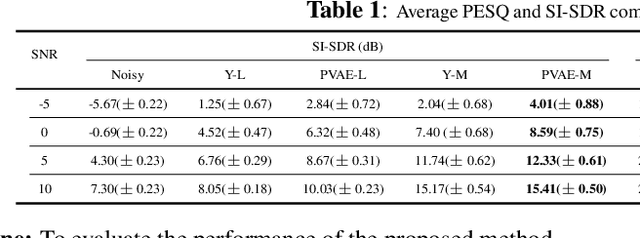
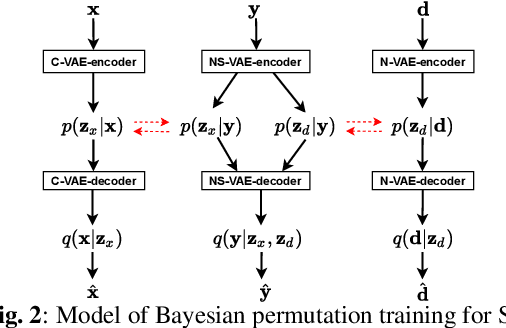
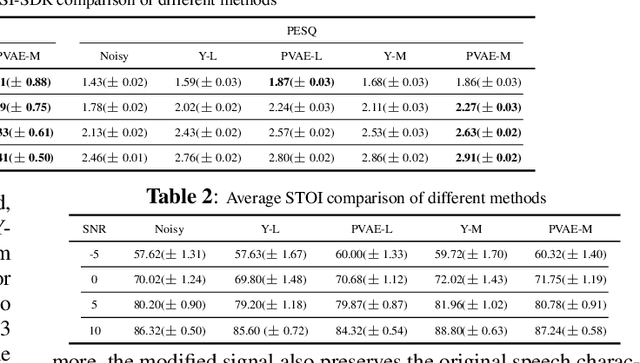
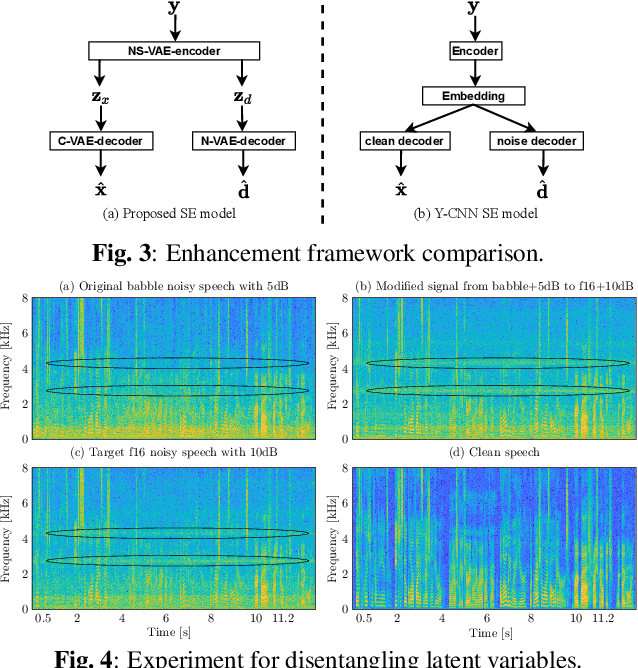
Recently, variational autoencoder (VAE), a deep representation learning (DRL) model, has been used to perform speech enhancement (SE). However, to the best of our knowledge, current VAE-based SE methods only apply VAE to the model speech signal, while noise is modeled using the traditional non-negative matrix factorization (NMF) model. One of the most important reasons for using NMF is that these VAE-based methods cannot disentangle the speech and noise latent variables from the observed signal. Based on Bayesian theory, this paper derives a novel variational lower bound for VAE, which ensures that VAE can be trained in supervision, and can disentangle speech and noise latent variables from the observed signal. This means that the proposed method can apply the VAE to model both speech and noise signals, which is totally different from the previous VAE-based SE works. More specifically, the proposed DRL method can learn to impose speech and noise signal priors to different sets of latent variables for SE. The experimental results show that the proposed method can not only disentangle speech and noise latent variables from the observed signal but also obtain a higher scale-invariant signal-to-distortion ratio and speech quality score than the similar deep neural network-based (DNN) SE method.