 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multi-Modal Forecasting: Integrating Static and Dynamic Features
May 21, 2025Time series forecasting plays a crucial role in various applications, particularly in healthcare, where accurate predictions of future health trajectories can significantly impact clinical decision-making. Ensuring transparency and explainability of the models responsible for these tasks is essential for their adoption in critical settings. Recent work has explored a top-down approach to bi-level transparency, focusing on understanding trends and properties of predicted time series using static features. In this work, we extend this framework by incorporating exogenous time series features alongside static features in a structured manner, while maintaining cohesive interpretation. Our approach leverages the insights of trajectory comprehension to introduce an encoding mechanism for exogenous time series, where they are decomposed into meaningful trends and properties, enabling the extraction of interpretable patterns. Through experiments on several synthetic datasets, we demonstrate that our approach remains predictive while preserving interpretability and robustness. This work represents a step towards developing robust, and generalized time series forecasting models. The code is available at https://github.com/jeremy-qin/TIMEVIEW
Enhancing Healthcare LLM Trust with Atypical Presentations Recalibration
Sep 05, 2024

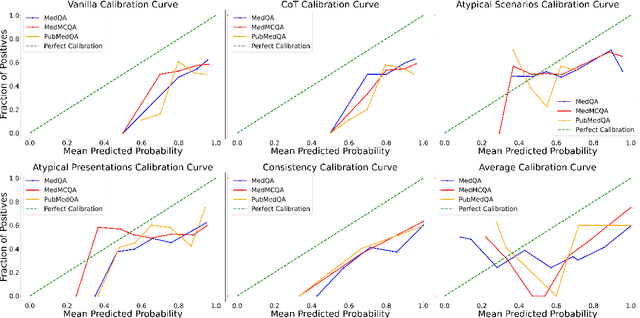

Black-box large language models (LLMs) are increasingly deployed in various environments, making it essential for these models to effectively convey their confidence and uncertainty, especially in high-stakes settings. However, these models often exhibit overconfidence, leading to potential risks and misjudgments. Existing techniques for eliciting and calibrating LLM confidence have primarily focused on general reasoning datasets, yielding only modest improvements. Accurate calibration is crucial for informed decision-making and preventing adverse outcomes but remains challenging due to the complexity and variability of tasks these models perform. In this work, we investigate the miscalibration behavior of black-box LLMs within the healthcare setting. We propose a novel method, \textit{Atypical Presentations Recalibration}, which leverages atypical presentations to adjust the model's confidence estimates. Our approach significantly improves calibration, reducing calibration errors by approximately 60\% on three medical question answering datasets and outperforming existing methods such as vanilla verbalized confidence, CoT verbalized confidence and others. Additionally, we provide an in-depth analysis of the role of atypicality within the recalibration framework.