 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic trajectory recognition in Active Target Time Projection Chambers data by means of hierarchical clustering
Aug 20, 2018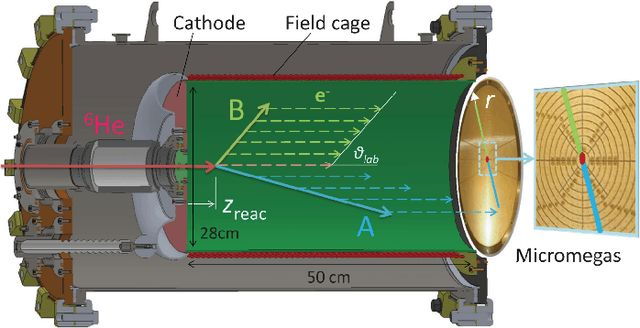

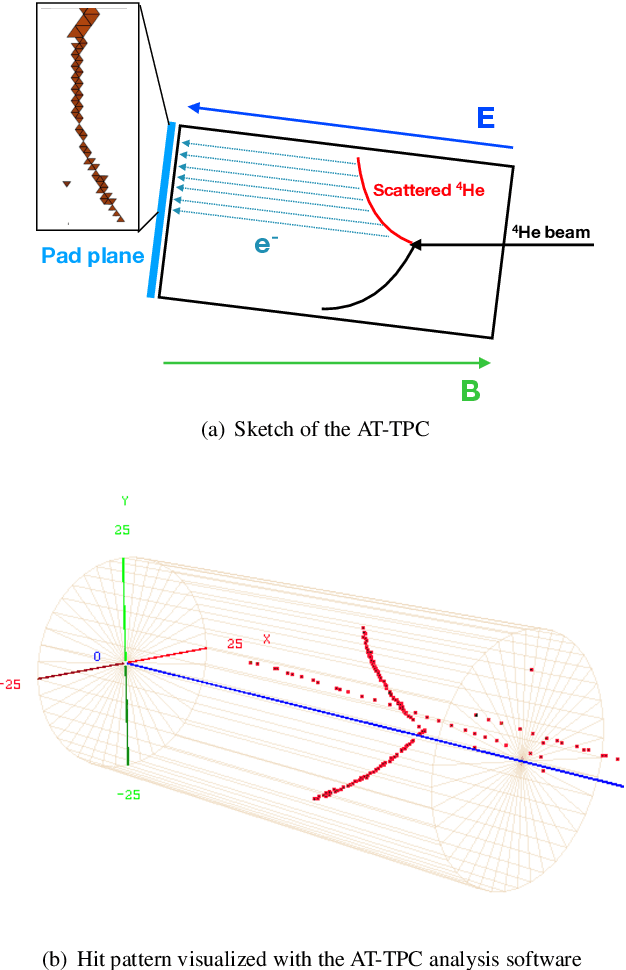
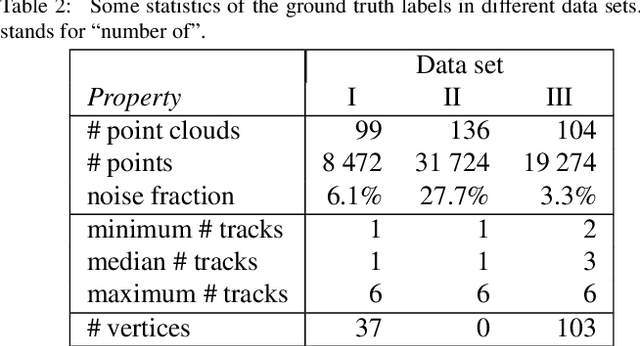
The automatic reconstruction of three-dimensional particle tracks from Active Target Time Projection Chambers data can be a challenging task, especially in the presence of noise. In this article, we propose a non-parametric algorithm that is based on the idea of clustering point triplets instead of the original points. We define an appropriate distance measure on point triplets and then apply a single-link hierarchical clustering on the triplets. Compared to parametric approaches like RANSAC or the Hough transform, the new algorithm has the advantage of potentially finding trajectories even of shapes that are not known beforehand. This feature is particularly important in low-energy nuclear physics experiments with Active Targets operating inside a magnetic field. The algorithm has been validated using data from experiments performed with the Active Target Time Projection Chamber developed at the National Superconducting Cyclotron Laboratory (NSCL).The results demonstrate the capability of the algorithm to identify and isolate particle tracks that describe non-analytical trajectories. For curved tracks, the vertex detection recall was 86\% and the precision 94\%. For straight tracks, the vertex detection recall was 96\% and the precision 98\%. In the case of a test set containing only straight linear tracks, the algorithm performed better than an iterative Hough transform.
Paired Comparison Sentiment Scores
Jul 10, 2018

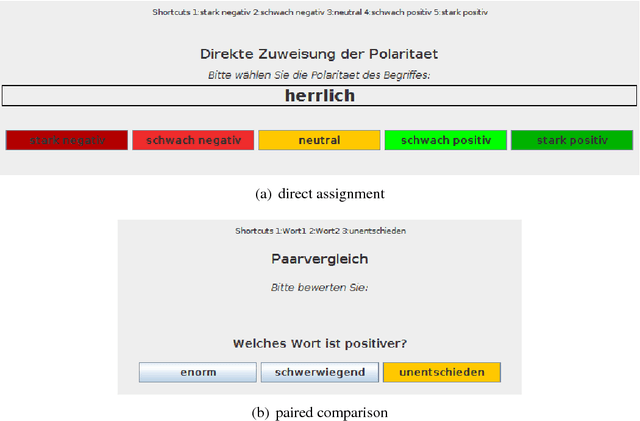
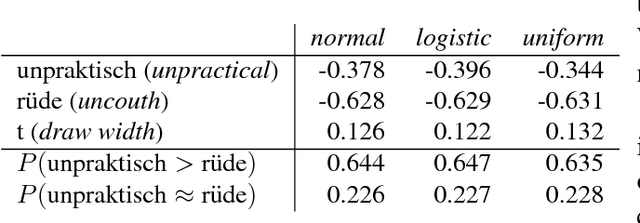
The method of paired comparisons is an established method in psychology. In this article, it is applied to obtain continuous sentiment scores for words from comparisons made by test persons. We created an initial lexicon with $n=199$ German words from a two-fold all-pair comparison experiment with ten different test persons. From the probabilistic models taken into account, the logistic model showed the best agreement with the results of the comparison experiment. The initial lexicon can then be used in different ways. One is to create special purpose sentiment lexica through the addition of arbitrary words that are compared with some of the initial words by test persons. A cross-validation experiment suggests that only about 18 two-fold comparisons are necessary to estimate the score of a new, yet unknown word, provided these words are selected by a modification of a method by Silverstein & Farrell. Another application of the initial lexicon is the evaluation of automatically created corpus-based lexica. By such an evaluation, we compared the corpus-based lexica SentiWS, SenticNet, and SentiWordNet, of which SenticNet 4 performed best. This technical report is a corrected and extended version of a presentation made at the ICDM Sentire workshop in 2016.