 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Approach for Metadata Extraction from German Scientific Publications
Nov 10, 2021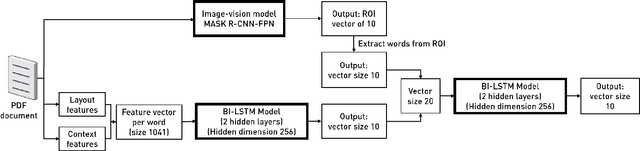

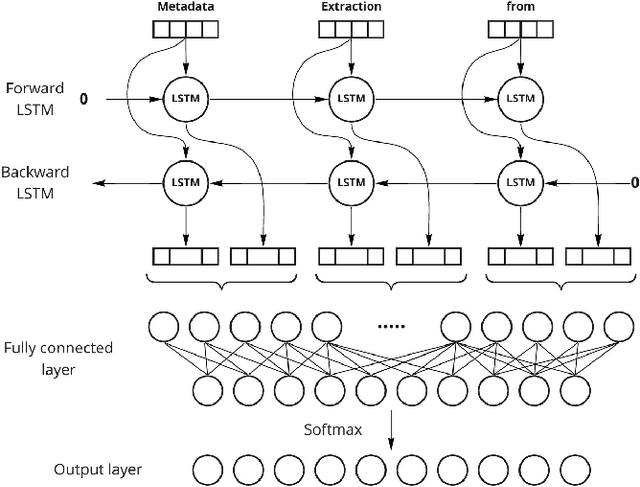
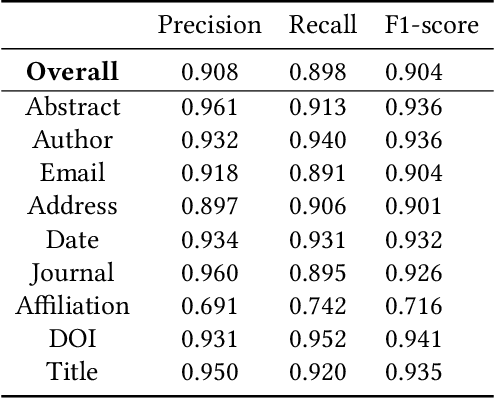
Nowadays, metadata information is often given by the authors themselves upon submission. However, a significant part of already existing research papers have missing or incomplete metadata information. German scientific papers come in a large variety of layouts which makes the extraction of metadata a non-trivial task that requires a precise way to classify the metadata extracted from the documents. In this paper, we propose a multimodal deep learning approach for metadata extraction from scientific papers in the German language. We consider multiple types of input data by combining natural language processing and image vision processing. This model aims to increase the overall accuracy of metadata extraction compared to other state-of-the-art approaches. It enables the utilization of both spatial and contextual features in order to achieve a more reliable extraction. Our model for this approach was trained on a dataset consisting of around 8800 documents and is able to obtain an overall F1-score of 0.923.