 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scarcity to Scale: A Release-Level Analysis of the Pashto Common Voice Dataset
Feb 15, 2026Large, openly licensed speech datasets are essential for building automatic speech recognition (ASR) systems, yet many widely spoken languages remain underrepresented in public resources. Pashto, spoken by more than 60 million people, has historically lacked large-scale openly licensed speech data suitable for modern ASR development. This paper presents a release-level analysis of the Pashto component of the Mozilla Common Voice corpus, focusing on version 24.0 (December 2025) and contextualizing trends across major releases. We document rapid growth from 1.49 recorded hours in mid-2023 to 2,768.7 total hours in 2025, including 975.89 validated hours available for supervised ASR training. Beyond scale, we analyze validation throughput, contributor participation inequality, demographic metadata completeness, and sentence-level concentration in the validated subset. We find that participation is extremely concentrated (Gini = 0.941), age representation is strongly skewed toward young adults, and 41.97\% of clips lack self-reported gender labels, limiting subgroup auditing based on metadata. At the textual level, prompt reuse is moderate: 35.88\% of unique sentences account for 50\% of validated clips, suggesting that structural concentration is driven primarily by uneven contributor activity rather than dominance of a small prompt set. These results provide a quantitative audit of a rapidly scaling low-resource speech corpus and highlight practical priorities for improving dataset maturity, including expanded validation capacity and broader demographic participation.
Gpt-4: A Review on Advancements and Opportunities in Natural Language Processing
May 04, 2023Generative Pre-trained Transformer 4 (GPT-4) is the fourth-generation language model in the GPT series, developed by OpenAI, which promises significant advancements in the field of natural language processing (NLP). In this research article, we have discussed the features of GPT-4, its potential applications, and the challenges that it might face. We have also compared GPT-4 with its predecessor, GPT-3. GPT-4 has a larger model size (more than one trillion), better multilingual capabilities, improved contextual understanding, and reasoning capabilities than GPT-3. Some of the potential applications of GPT-4 include chatbots, personal assistants, language translation, text summarization, and question-answering. However, GPT-4 poses several challenges and limitations such as computational requirements, data requirements, and ethical concerns.
Employing Hybrid Deep Neural Networks on Dari Speech
May 04, 2023This paper is an extension of our previous conference paper. In recent years, there has been a growing interest among researchers in developing and improving speech recognition systems to facilitate and enhance human-computer interaction. Today, Automatic Speech Recognition (ASR) systems have become ubiquitous, used in everything from games to translation systems, robots, and more. However, much research is still needed on speech recognition systems for low-resource languages. This article focuses on the recognition of individual words in the Dari language using the Mel-frequency cepstral coefficients (MFCCs) feature extraction method and three different deep neural network models: Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Multilayer Perceptron (MLP), as well as two hybrid models combining CNN and RNN. We evaluate these models using an isolated Dari word corpus that we have created, consisting of 1000 utterances for 20 short Dari terms. Our study achieved an impressive average accuracy of 98.365%.
Tuning Traditional Language Processing Approaches for Pashto Text Classification
May 04, 2023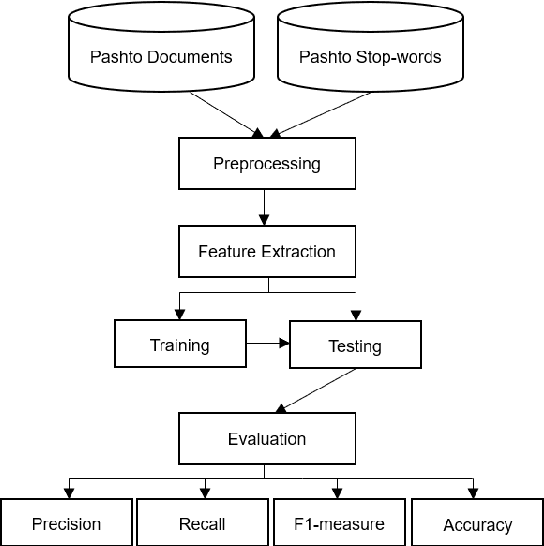



Today text classification becomes critical task for concerned individuals for numerous purposes. Hence, several researches have been conducted to develop automatic text classification for national and international languages. However, the need for an automatic text categorization system for local languages is felt. The main aim of this study is to establish a Pashto automatic text classification system. In order to pursue this work, we built a Pashto corpus which is a collection of Pashto documents due to the unavailability of public datasets of Pashto text documents. Besides, this study compares several models containing both statistical and neural network machine learning techniques including Multilayer Perceptron (MLP), Support Vector Machine (SVM), K Nearest Neighbor (KNN), decision tree, gaussian na\"ive Bayes, multinomial na\"ive Bayes, random forest, and logistic regression to discover the most effective approach. Moreover, this investigation evaluates two different feature extraction methods including unigram, and Time Frequency Inverse Document Frequency (IFIDF). Subsequently, this research obtained average testing accuracy rate 94% using MLP classification algorithm and TFIDF feature extraction method in this context.
* arXiv admin note: substantial text overlap with arXiv:2305.03201
Enhancing Pashto Text Classification using Language Processing Techniques for Single And Multi-Label Analysis
May 04, 2023



Text classification has become a crucial task in various fields, leading to a significant amount of research on developing automated text classification systems for national and international languages. However, there is a growing need for automated text classification systems that can handle local languages. This study aims to establish an automated classification system for Pashto text. To achieve this goal, we constructed a dataset of Pashto documents and applied various models, including statistical and neural machine learning models such as DistilBERT-base-multilingual-cased, Multilayer Perceptron, Support Vector Machine, K Nearest Neighbor, decision tree, Gaussian na\"ive Bayes, multinomial na\"ive Bayes, random forest, and logistic regression, to identify the most effective approach. We also evaluated two different feature extraction methods, bag of words and Term Frequency Inverse Document Frequency. The study achieved an average testing accuracy rate of 94% using the MLP classification algorithm and TFIDF feature extraction method in single-label multiclass classification. Similarly, MLP+TFIDF yielded the best results, with an F1-measure of 0.81. Furthermore, the use of pre-trained language representation models, such as DistilBERT, showed promising results for Pashto text classification; however, the study highlights the importance of developing a specific tokenizer for a particular language to achieve reasonable results.