 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Words Do We Use to Lie?: Word Choice in Deceptive Messages
Oct 01, 2017Text messaging is the most widely used form of computer- mediated communication (CMC). Previous findings have shown that linguistic factors can reliably indicate messages as deceptive. For example, users take longer and use more words to craft deceptive messages than they do truthful messages. Existing research has also examined how factors, such as student status and gender, affect rates of deception and word choice in deceptive messages. However, this research has been limited by small sample sizes and has returned contradicting findings. This paper aims to address these issues by using a dataset of text messages collected from a large and varied set of participants using an Android messaging application. The results of this paper show significant differences in word choice and frequency of deceptive messages between male and female participants, as well as between students and non-students.
"Draw My Topics": Find Desired Topics fast from large scale of Corpus
Feb 03, 2016
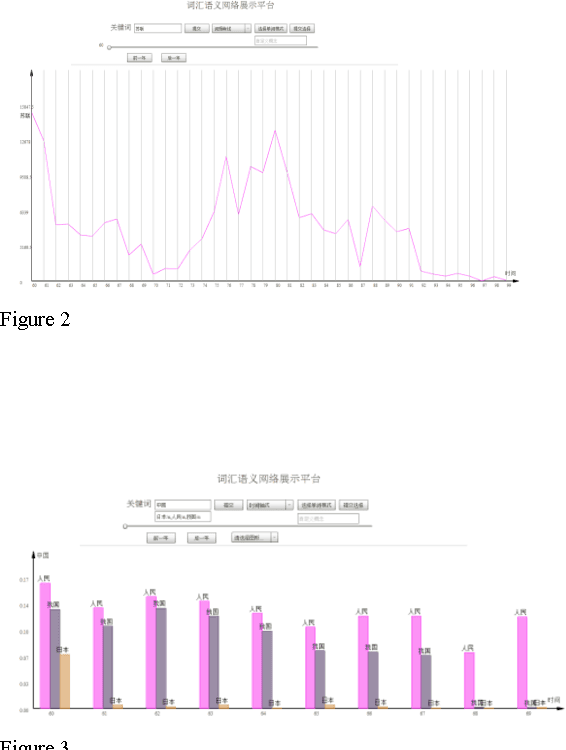

We develop the "Draw My Topics" toolkit, which provides a fast way to incorporate social scientists' interest into standard topic modelling. Instead of using raw corpus with primitive processing as input, an algorithm based on Vector Space Model and Conditional Entropy are used to connect social scientists' willingness and unsupervised topic models' output. Space for users' adjustment on specific corpus of their interest is also accommodated. We demonstrate the toolkit's use on the Diachronic People's Daily Corpus in Chinese.