 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of AI to formal methods -- an analysis of current trends
Nov 22, 2024

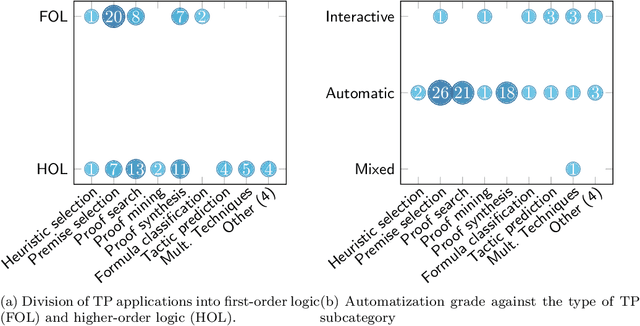
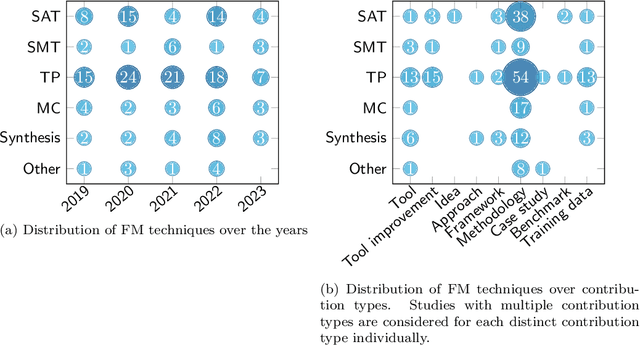
With artificial intelligence (AI) being well established within the daily lives of research communities, we turn our gaze toward an application area that appears intuitively unsuited for probabilistic decision-making: the area of formal methods (FM). FM aim to provide sound and understandable reasoning about problems in computer science, which seemingly collides with the black-box nature that inhibits many AI approaches. However, many researchers have crossed this gap and applied AI techniques to enhance FM approaches. As this dichotomy of FM and AI sparked our interest, we conducted a systematic mapping study to map the current landscape of research publications. In this study, we investigate the previous five years of applied AI to FM (2019-2023), as these correspond to periods of high activity. This investigation results in 189 entries, which we explore in more detail to find current trends, highlight research gaps, and give suggestions for future research.
Evaluating the Impact of Loss Function Variation in Deep Learning for Classification
Oct 28, 2022The loss function is arguably among the most important hyperparameters for a neural network. Many loss functions have been designed to date, making a correct choice nontrivial. However, elaborate justifications regarding the choice of the loss function are not made in related work. This is, as we see it, an indication of a dogmatic mindset in the deep learning community which lacks empirical foundation. In this work, we consider deep neural networks in a supervised classification setting and analyze the impact the choice of loss function has onto the training result. While certain loss functions perform suboptimally, our work empirically shows that under-represented losses such as the KL Divergence can outperform the State-of-the-Art choices significantly, highlighting the need to include the loss function as a tuned hyperparameter rather than a fixed choice.
Towards Equalised Odds as Fairness Metric in Academic Performance Prediction
Sep 29, 2022The literature for fairness-aware machine learning knows a plethora of different fairness notions. It is however wellknown, that it is impossible to satisfy all of them, as certain notions contradict each other. In this paper, we take a closer look at academic performance prediction (APP) systems and try to distil which fairness notions suit this task most. For this, we scan recent literature proposing guidelines as to which fairness notion to use and apply these guidelines onto APP. Our findings suggest equalised odds as most suitable notion for APP, based on APP's WYSIWYG worldview as well as potential long-term improvements for the population.