 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining End-to-End Keyword Search with Automatically Discovered Acoustic Units
Jul 05, 2024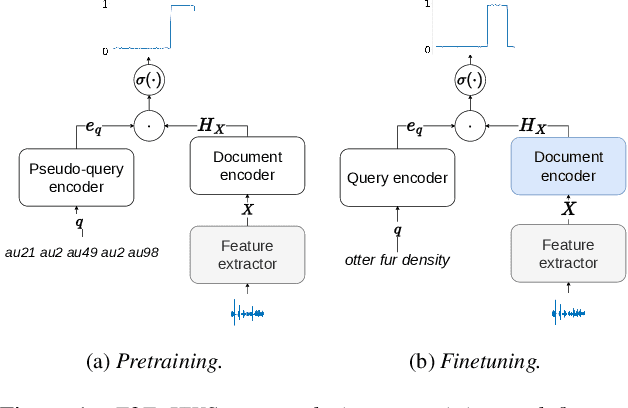


End-to-end (E2E) keyword search (KWS) has emerged as an alternative and complimentary approach to conventional keyword search which depends on the output of automatic speech recognition (ASR) systems. While E2E methods greatly simplify the KWS pipeline, they generally have worse performance than their ASR-based counterparts, which can benefit from pretraining with untranscribed data. In this work, we propose a method for pretraining E2E KWS systems with untranscribed data, which involves using acoustic unit discovery (AUD) to obtain discrete units for untranscribed data and then learning to locate sequences of such units in the speech. We conduct experiments across languages and AUD systems: we show that finetuning such a model significantly outperforms a model trained from scratch, and the performance improvements are generally correlated with the quality of the AUD system used for pretraining.