 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
HiPPO-KAN: Efficient KAN Model for Time Series Analysis
Oct 19, 2024



In this study, we introduces a parameter-efficient model that outperforms traditional models in time series forecasting, by integrating High-order Polynomial Projection (HiPPO) theory into the Kolmogorov-Arnold network (KAN) framework. This HiPPO-KAN model achieves superior performance on long sequence data without increasing parameter count. Experimental results demonstrate that HiPPO-KAN maintains a constant parameter count while varying window sizes and prediction horizons, in contrast to KAN, whose parameter count increases linearly with window size. Surprisingly, although the HiPPO-KAN model keeps a constant parameter count as increasing window size, it significantly outperforms KAN model at larger window sizes. These results indicate that HiPPO-KAN offers significant parameter efficiency and scalability advantages for time series forecasting. Additionally, we address the lagging problem commonly encountered in time series forecasting models, where predictions fail to promptly capture sudden changes in the data. We achieve this by modifying the loss function to compute the MSE directly on the coefficient vectors in the HiPPO domain. This adjustment effectively resolves the lagging problem, resulting in predictions that closely follow the actual time series data. By incorporating HiPPO theory into KAN, this study showcases an efficient approach for handling long sequences with improved predictive accuracy, offering practical contributions for applications in large-scale time series data.
On the ability of CNNs to extract color invariant intensity based features for image classification
Jul 13, 2023Convolutional neural networks (CNNs) have demonstrated remarkable success in vision-related tasks. However, their susceptibility to failing when inputs deviate from the training distribution is well-documented. Recent studies suggest that CNNs exhibit a bias toward texture instead of object shape in image classification tasks, and that background information may affect predictions. This paper investigates the ability of CNNs to adapt to different color distributions in an image while maintaining context and background. The results of our experiments on modified MNIST and FashionMNIST data demonstrate that changes in color can substantially affect classification accuracy. The paper explores the effects of various regularization techniques on generalization error across datasets and proposes a minor architectural modification utilizing the dropout regularization in a novel way that enhances model reliance on color-invariant intensity-based features for improved classification accuracy. Overall, this work contributes to ongoing efforts to understand the limitations and challenges of CNNs in image classification tasks and offers potential solutions to enhance their performance.
Heterogeneous Causal Learning for Effectiveness Optimization in User Marketing
Apr 21, 2020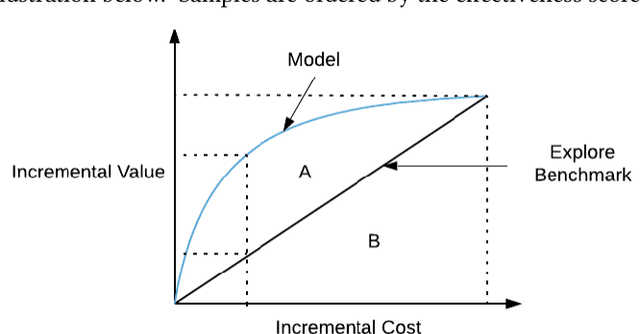

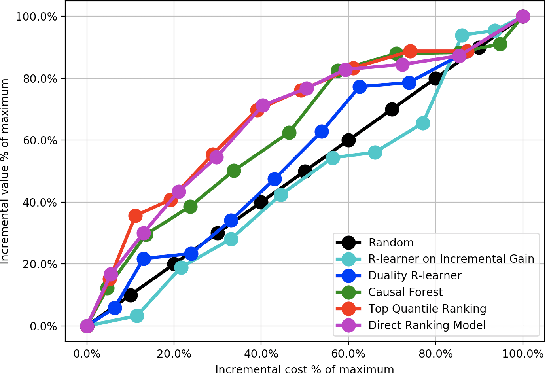

User marketing is a key focus of consumer-based internet companies. Learning algorithms are effective to optimize marketing campaigns which increase user engagement, and facilitates cross-marketing to related products. By attracting users with rewards, marketing methods are effective to boost user activity in the desired products. Rewards incur significant cost that can be off-set by increase in future revenue. Most methodologies rely on churn predictions to prevent losing users to make marketing decisions, which cannot capture up-lift across counterfactual outcomes with business metrics. Other predictive models are capable of estimating heterogeneous treatment effects, but fail to capture the balance of cost versus benefit. We propose a treatment effect optimization methodology for user marketing. This algorithm learns from past experiments and utilizes novel optimization methods to optimize cost efficiency with respect to user selection. The method optimizes decisions using deep learning optimization models to treat and reward users, which is effective in producing cost-effective, impactful marketing campaigns. Our methodology demonstrates superior algorithmic flexibility with integration with deep learning methods and dealing with business constraints. The effectiveness of our model surpasses the quasi-oracle estimation (R-learner) model and causal forests. We also established evaluation metrics that reflect the cost-efficiency and real-world business value. Our proposed constrained and direct optimization algorithms outperform by 24.6% compared with the best performing method in prior art and baseline methods. The methodology is useful in many product scenarios such as optimal treatment allocation and it has been deployed in production world-wide.