 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Noise with Generative Adversarial Networks: Explorations with Classical Random Process Models
Jul 03, 2022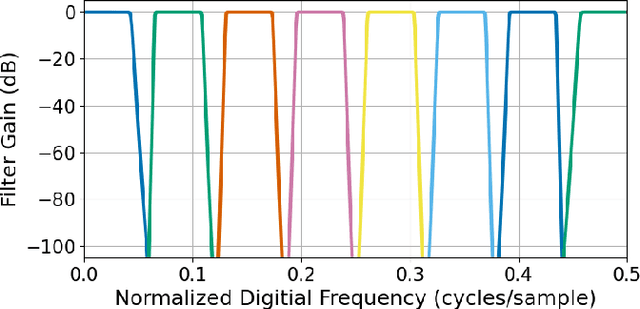
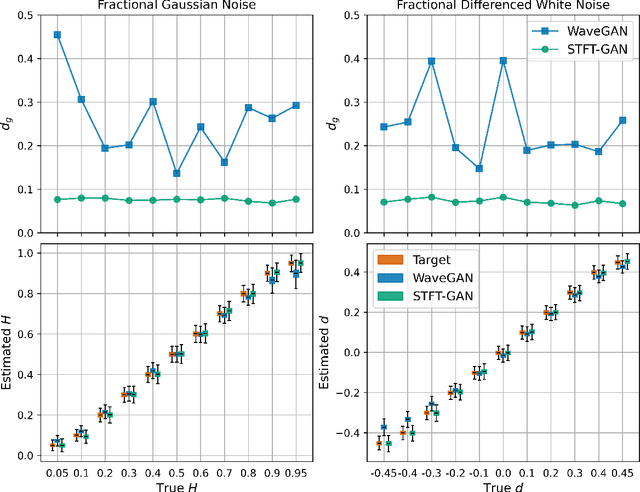
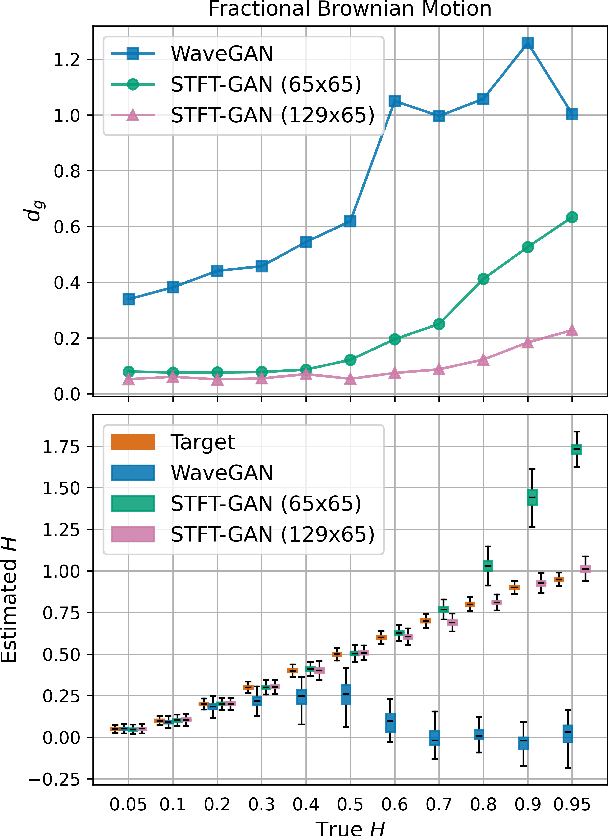
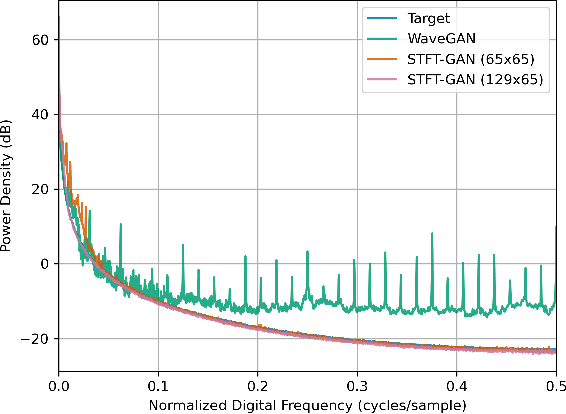
Random noise arising from physical processes is an inherent characteristic of measurements and a limiting factor for most signal processing tasks. Given the recent interest in generative adversarial networks (GANs) for data-driven signal modeling, it is important to determine to what extent GANs can faithfully reproduce noise in target data sets. In this paper, we present an empirical investigation that aims to shed light on this issue for time series. Namely, we examine the ability of two general-purpose time-series GANs, a direct time-series model and an image-based model using a short-time Fourier transform (STFT) representation, to learn a broad range of noise types commonly encountered in electronics and communication systems: band-limited thermal noise, power law noise, shot noise, and impulsive noise. We find that GANs are capable of learning many noise types, although they predictably struggle when the GAN architecture is not well suited to some aspects of the noise, e.g., impulsive time-series with extreme outliers. Our findings provide insights into the capabilities and potential limitations of current approaches to time-series GANs and highlight areas for further research. In addition, our battery of tests provides a useful benchmark to aid the development of deep generative models for time series.
On the Feasibility of Modeling OFDM Communication Signals with Unsupervised Generative Adversarial Networks
Sep 10, 2021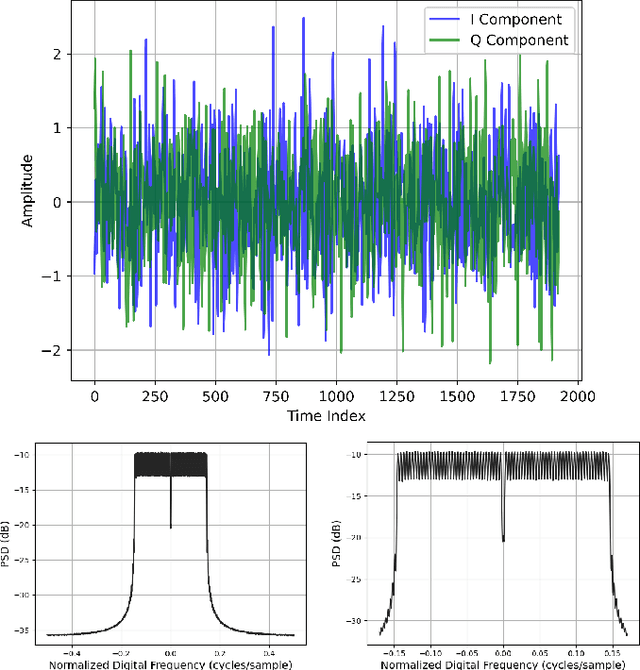
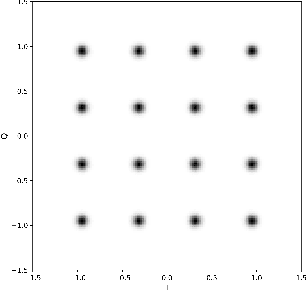
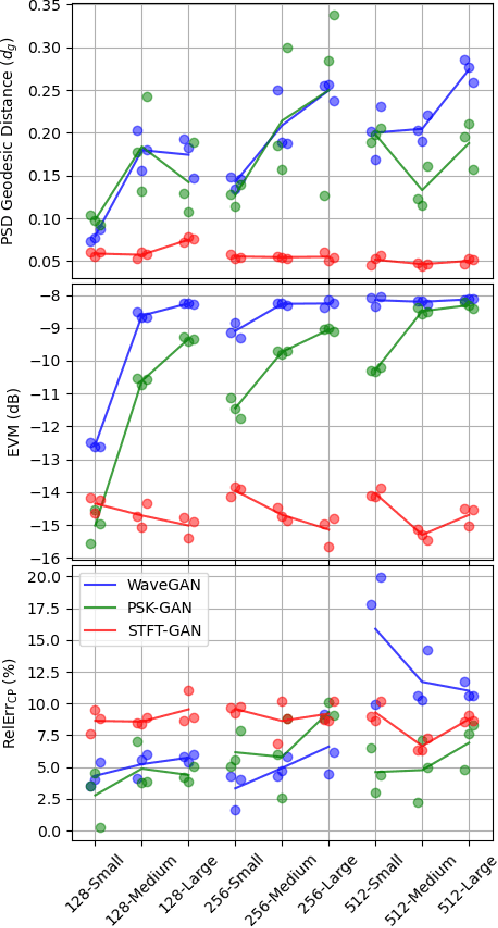
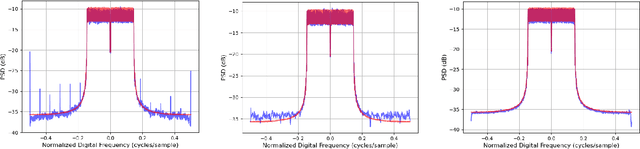
High-quality recordings of radio frequency (RF) emissions from commercial communication hardware in realistic environments are often needed to develop and assess spectrum-sharing technologies and practices, e.g., for training and testing spectrum sensing algorithms and for interference testing. Unfortunately, the time-consuming, expensive nature of such data collections together with data-sharing restrictions pose significant challenges that limit dataset availability. Furthermore, developing accurate models of real-world RF emissions from first principles is often very difficult because system parameters and implementation details are at best only partially known, and complex system dynamics are difficult to characterize. Hence, there is a need for flexible, data-driven methods that can leverage existing datasets to synthesize additional similar waveforms. One promising machine learning approach is unsupervised deep generative modeling with generative adversarial networks (GANs). To date, GANs for RF communication signals have not been studied thoroughly. In this paper, we present the first in-depth investigation of generated signal fidelity for GANs trained with baseband orthogonal frequency-division multiplexing (OFDM) signals, where each subcarrier is digitally modulated with quadrature amplitude modulation (QAM). Building on prior GAN methods, we propose two novel GAN models and evaluate their performance using simulated datasets with known ground truth. Specifically, we investigate model performance with respect to increasing dataset complexity over a range of OFDM parameters and conditions, including fading channels. The findings presented here inform the feasibility of use-cases and provide a foundation for further investigations into deep generative models for RF communication signals.
Improving on Q & A Recurrent Neural Networks Using Noun-Tagging
Jul 12, 2018
Often, more time is spent on finding a model that works well, rather than tuning the model and working directly with the dataset. Our research began as an attempt to improve upon a simple Recurrent Neural Network for answering "simple" first-order questions (QA-RNN), developed by Ferhan Ture and Oliver Jojic, from Comcast Labs, using the SimpleQuestions dataset. Their baseline model, a bidirectional, 2-layer LSTM RNN and a GRU RNN, have accuracies of 0.94 and 0.90, for entity detection and relation prediction, respectively. We fine tuned these models by doing substantial hyper-parameter tuning, getting resulting accuracies of 0.70 and 0.80, for entity detection and relation prediction, respectively. An accuracy of 0.984 was obtained on entity detection using a 1-layer LSTM, where preprocessing was done by removing all words not part of a noun chunk from the question. 100% of the dataset was available for relation prediction, but only 20% of the dataset, was available for entity detection, which we believe to be much of the reason for our initial difficulties in replicating their result, despite the fact we were able to improve on their entity detection results.