 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep RL with Hierarchical Action Exploration for Dialogue Generation
Mar 22, 2023Conventionally, since the natural language action space is astronomical, approximate dynamic programming applied to dialogue generation involves policy improvement with action sampling. However, such a practice is inefficient for reinforcement learning (RL) because the eligible (high action value) responses are very sparse, and the greedy policy sustained by the random sampling is flabby. This paper shows that the performance of dialogue policy positively correlated with sampling size by theoretical and experimental. We introduce a novel dual-granularity Q-function to alleviate this limitation by exploring the most promising response category to intervene in the sampling. It extracts the actions following the grained hierarchy, which can achieve the optimum with fewer policy iterations. Our approach learns in the way of offline RL from multiple reward functions designed to recognize human emotional details. Empirical studies demonstrate that our algorithm outperforms the baseline methods. Further verification presents that ours can generate responses with higher expected rewards and controllability.
Towards Building a Personalized Dialogue Generator via Implicit User Persona Detection
Apr 15, 2022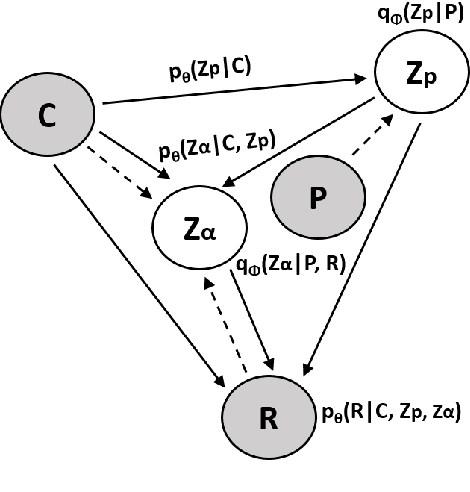
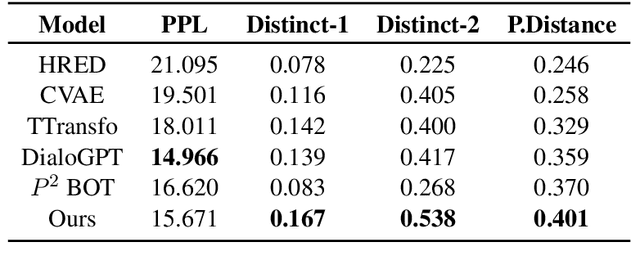
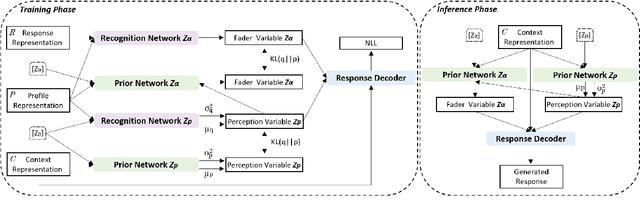

Current works in the generation of personalized dialogue primarily contribute to the agent avoiding contradictory persona and driving the response more informative. However, we found that the generated responses from these models are mostly self-centered with little care for the other party since they ignore the user's persona. Moreover, we consider high-quality transmission is essentially built based on apprehending the persona of the other party. Motivated by this, we propose a novel personalized dialogue generator by detecting implicit user persona. Because it's difficult to collect a large number of personas for each user, we attempt to model the user's potential persona and its representation from the dialogue absence of any external information. Perception variable and fader variable are conceived utilizing Conditional Variational Inference. The two latent variables simulate the process of people being aware of the other party's persona and producing the corresponding expression in conversation. Finally, Posterior-discriminated Regularization is presented to enhance the training procedure. Empirical studies demonstrate that compared with the state-of-the-art methods, ours is more concerned with the user's persona and outperforms in evaluations.