 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Retrieval in QA Systems with Derived Feature Association
Oct 02, 2024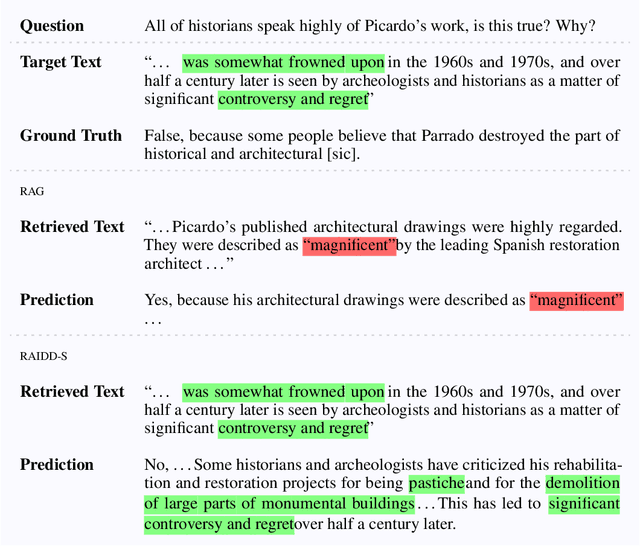
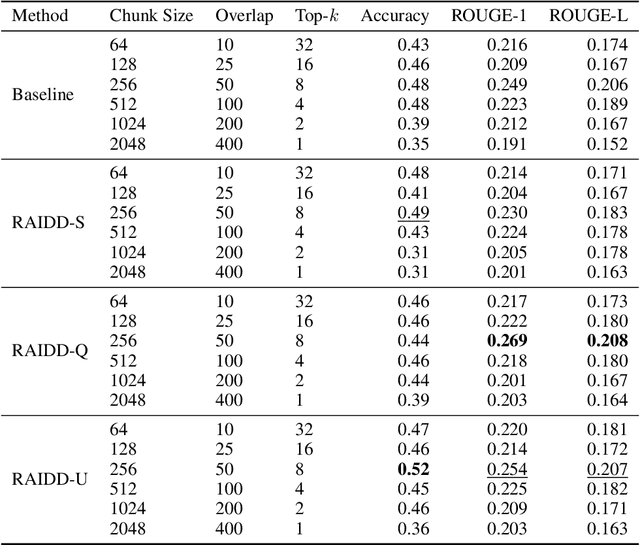
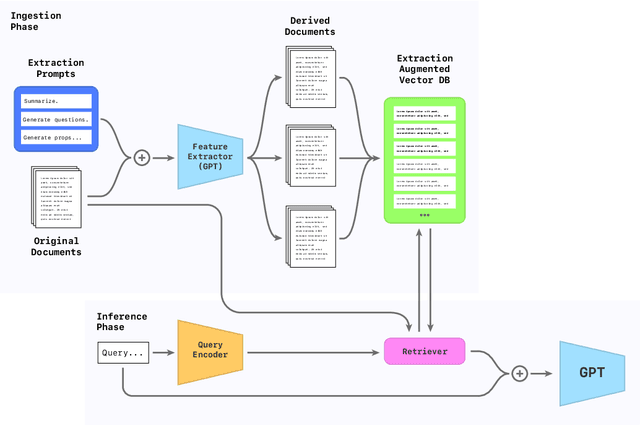
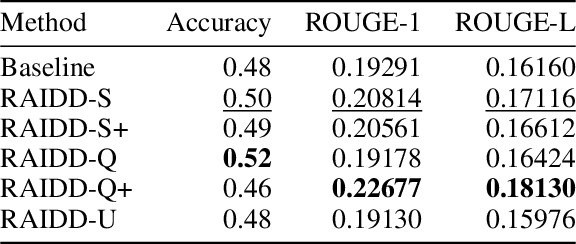
Retrieval augmented generation (RAG) has become the standard in long context question answering (QA) systems. However, typical implementations of RAG rely on a rather naive retrieval mechanism, in which texts whose embeddings are most similar to that of the query are deemed most relevant. This has consequences in subjective QA tasks, where the most relevant text may not directly contain the answer. In this work, we propose a novel extension to RAG systems, which we call Retrieval from AI Derived Documents (RAIDD). RAIDD leverages the full power of the LLM in the retrieval process by deriving inferred features, such as summaries and example questions, from the documents at ingest. We demonstrate that this approach significantly improves the performance of RAG systems on long-context QA tasks.
Patch-Based Deep Unsupervised Image Segmentation using Graph Cuts
Nov 01, 2023Unsupervised image segmentation aims at grouping different semantic patterns in an image without the use of human annotation. Similarly, image clustering searches for groupings of images based on their semantic content without supervision. Classically, both problems have captivated researchers as they drew from sound mathematical concepts to produce concrete applications. With the emergence of deep learning, the scientific community turned its attention to complex neural network-based solvers that achieved impressive results in those domains but rarely leveraged the advances made by classical methods. In this work, we propose a patch-based unsupervised image segmentation strategy that bridges advances in unsupervised feature extraction from deep clustering methods with the algorithmic help of classical graph-based methods. We show that a simple convolutional neural network, trained to classify image patches and iteratively regularized using graph cuts, naturally leads to a state-of-the-art fully-convolutional unsupervised pixel-level segmenter. Furthermore, we demonstrate that this is the ideal setting for leveraging the patch-level pairwise features generated by vision transformer models. Our results on real image data demonstrate the effectiveness of our proposed methodology.
Adversarially Robust Medical Classification via Attentive Convolutional Neural Networks
Oct 26, 2022Convolutional neural network-based medical image classifiers have been shown to be especially susceptible to adversarial examples. Such instabilities are likely to be unacceptable in the future of automated diagnoses. Though statistical adversarial example detection methods have proven to be effective defense mechanisms, additional research is necessary that investigates the fundamental vulnerabilities of deep-learning-based systems and how best to build models that jointly maximize traditional and robust accuracy. This paper presents the inclusion of attention mechanisms in CNN-based medical image classifiers as a reliable and effective strategy for increasing robust accuracy without sacrifice. This method is able to increase robust accuracy by up to 16% in typical adversarial scenarios and up to 2700% in extreme cases.
Modeling the Graphotactics of Low-Resource Languages Using Sequential GANs
Oct 26, 2022
Generative Adversarial Networks (GANs) have been shown to aid in the creation of artificial data in situations where large amounts of real data are difficult to come by. This issue is especially salient in the computational linguistics space, where researchers are often tasked with modeling the complex morphologic and grammatical processes of low-resource languages. This paper will discuss the implementation and testing of a GAN that attempts to model and reproduce the graphotactics of a language using only 100 example strings. These artificial, yet graphotactically compliant, strings are meant to aid in modeling the morphological inflection of low-resource languages.