 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Technique to Create Weaker Abstract Board Game Agents via Reinforcement Learning
Sep 01, 2022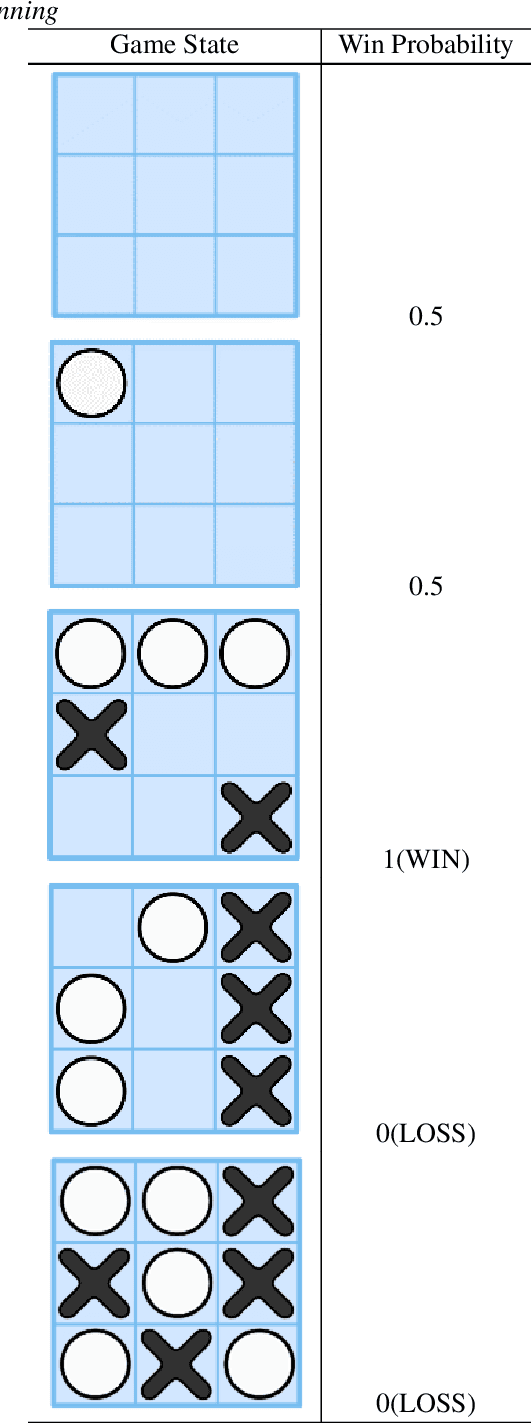
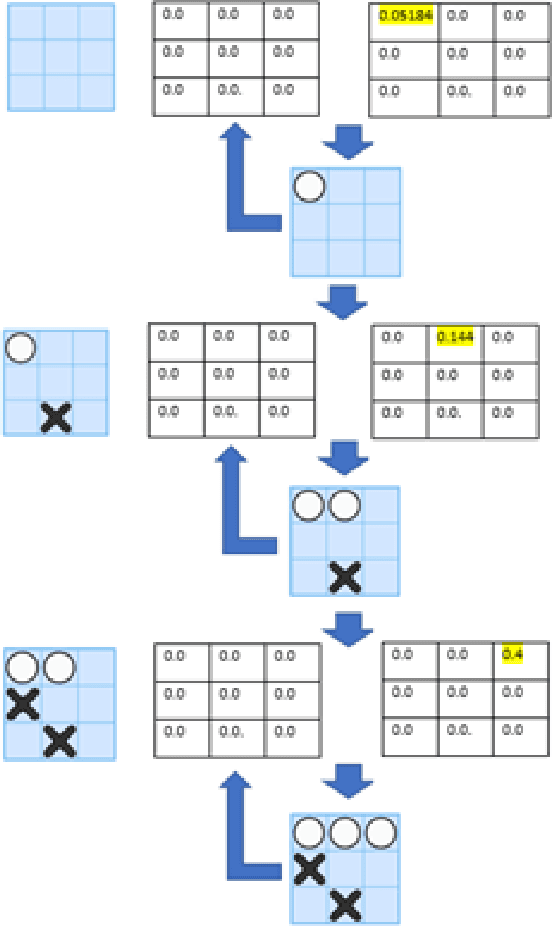


Board games, with the exception of solo games, need at least one other player to play. Because of this, we created Artificial Intelligent (AI) agents to play against us when an opponent is missing. These AI agents are created in a number of ways, but one challenge with these agents is that an agent can have superior ability compared to us. In this work, we describe how to create weaker AI agents that play board games. We use Tic-Tac-Toe, Nine-Men's Morris, and Mancala, and our technique uses a Reinforcement Learning model where an agent uses the Q-learning algorithm to learn these games. We show how these agents can learn to play the board game perfectly, and we then describe our approach to making weaker versions of these agents. Finally, we provide a methodology to compare AI agents.