 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWIM: An Attention-Only Model for Speech Quality Assessment Under Subjective Variance
Oct 16, 2024
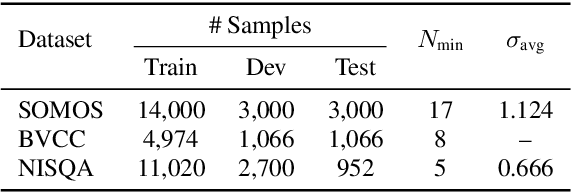
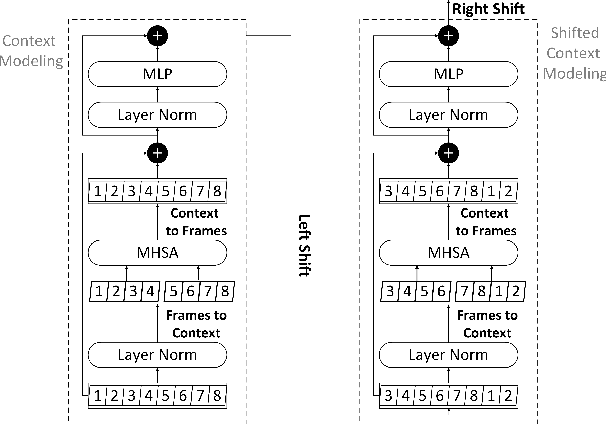
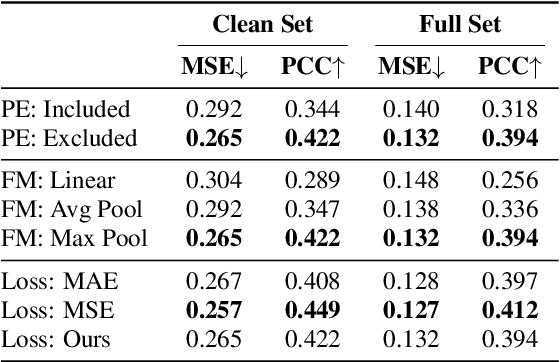
Speech quality is best evaluated by human feedback using mean opinion scores (MOS). However, variance in ratings between listeners can introduce noise in the true quality label of an utterance. Currently, deep learning networks including convolutional, recurrent, and attention-based architectures have been explored for quality estimation. This paper proposes an exclusively attention-based model involving a Swin Transformer for MOS estimation (SWIM). Our network captures local and global dependencies that reflect the acoustic properties of an utterance. To counteract subjective variance in MOS labels, we propose a normal distance-based objective that accounts for standard deviation in each label, and we avail a multistage self-teaching strategy to improve generalization further. Our model is significantly more compact than existing attention-based networks for quality estimation. Finally, our experiments on the Samsung Open Mean Opinion Score (SOMOS) dataset show improvement over existing baseline models when trained from scratch.