 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePR-CIM: a Variation-Aware Binary-Neural-Network Framework for Process-Resilient Computation-in-memory
Oct 19, 2021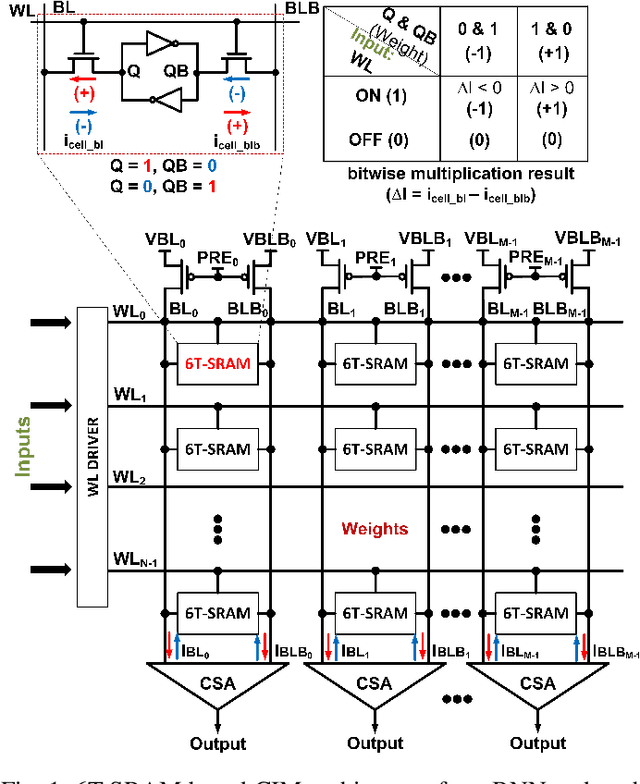
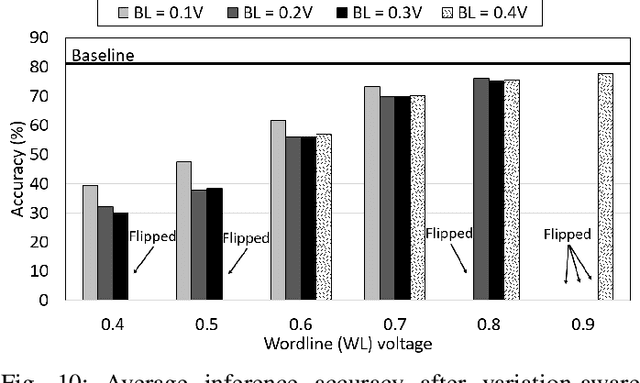
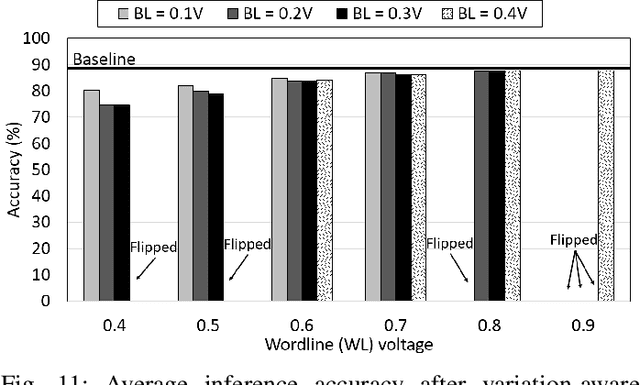
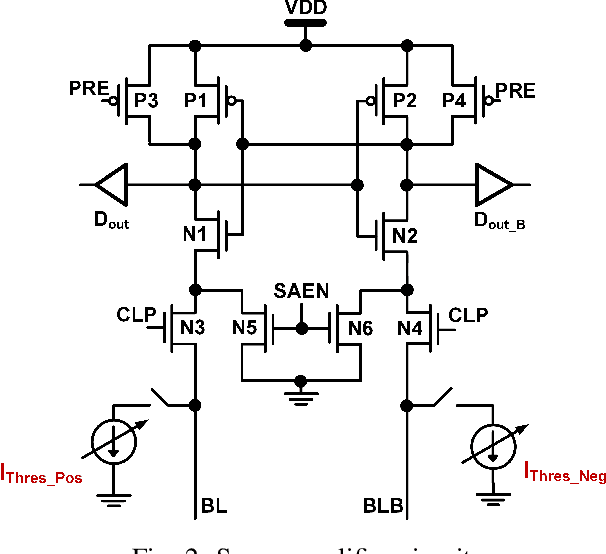
Binary neural networks (BNNs) that use 1-bit weights and activations have garnered interest as extreme quantization provides low power dissipation. By implementing BNNs as computing-in-memory (CIM), which computes multiplication and accumulations on memory arrays in an analog fashion, namely analog CIM, we can further improve the energy efficiency to process neural networks. However, analog CIMs suffer from the potential problem that process variation degrades the accuracy of BNNs. Our Monte-Carlo simulations show that in an SRAM-based analog CIM of VGG-9, the classification accuracy of CIFAR-10 is degraded even below 20% under process variations of 65nm CMOS. To overcome this problem, we present a variation-aware BNN framework. The proposed framework is developed for SRAM-based BNN CIMs since SRAM is most widely used as on-chip memory, however easily extensible to BNN CIMs based on other memories. Our extensive experimental results show that under process variation of 65nm CMOS, our framework significantly improves the CIFAR-10 accuracies of SRAM-based BNN CIMs, from 10% and 10.1% to 87.76% and 77.74% for VGG-9 and RESNET-18 respectively.
TCL: an ANN-to-SNN Conversion with Trainable Clipping Layers
Aug 11, 2020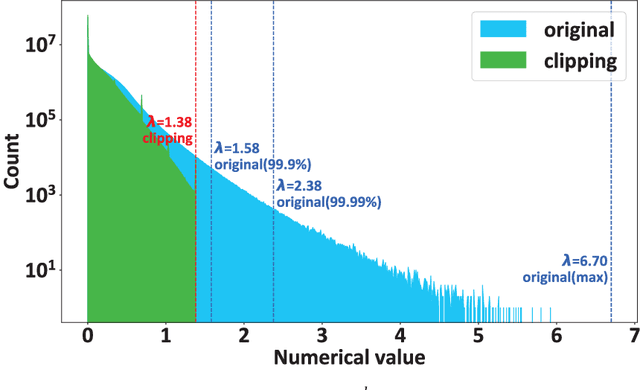
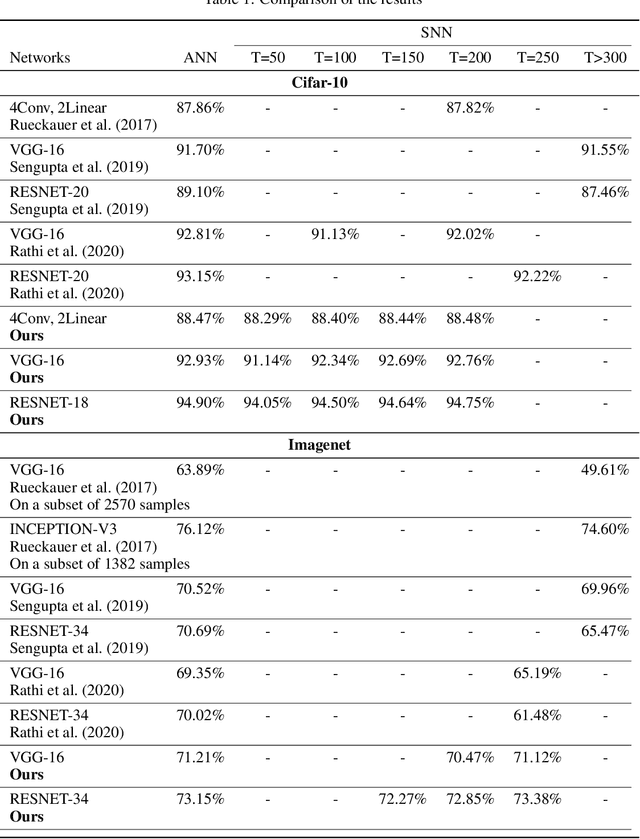
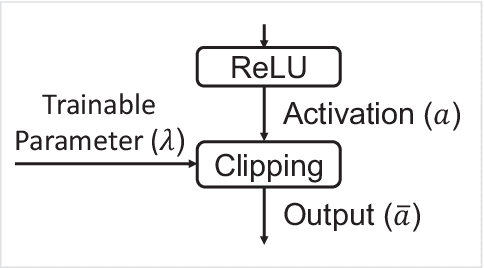
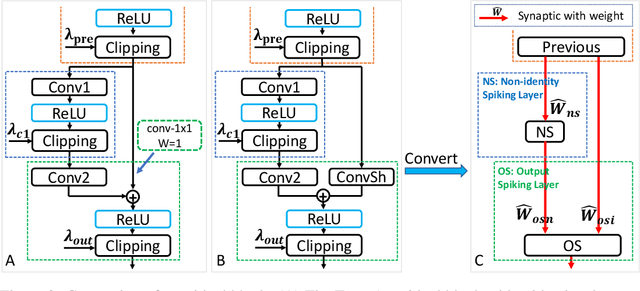
Spiking Neural Networks (SNNs) provide significantly lower power dissipationthan deep neural networks (DNNs), called as analog neural networks (ANNs) inthis work. Conventionally, SNNs have failed to arrive at the training accuraciesof ANNs. However, several recent researches have shown that this challenge canbe addressed by converting ANN to SNN instead of the direct training of SNNs.Nonetheless, the large latency of SNNs still limits their application, more prob-lematic for large size datasets such as Imagenet. It is challenging to overcome thisproblem since in SNNs, there is the trade-off relation between their accuracy and la-tency. In this work, we elegantly alleviate the problem by using a trainable clippinglayers, so called TCL. By combining the TCL with traditional data-normalizationtechniques, we respectively obtain 71.12% and 73.38% (on ImageNet) for VGG-16and RESNET-34 after the ANN to SNN conversion with the latency constraint of250 cycles.