 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrdu Digital Text Word Optical Character Recognition Using Permuted Auto Regressive Sequence Modeling
Aug 27, 2024
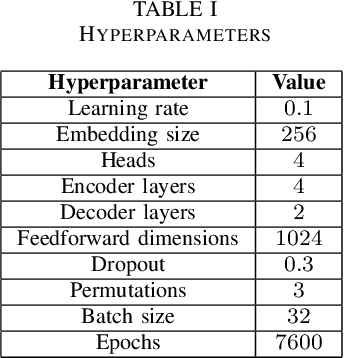
This research paper introduces an innovative word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text recognition. Utilizing transformer-based architectures and attention mechanisms, the model was trained on a comprehensive dataset of approximately 160,000 Urdu text images, achieving a character error rate (CER) of 0.178, which highlights its superior accuracy in recognizing Urdu characters. The model's strength lies in its unique architecture, incorporating the permuted autoregressive sequence (PARSeq) model, which allows for context-aware inference and iterative refinement by leveraging bidirectional context information to enhance recognition accuracy. Furthermore, its capability to handle a diverse range of Urdu text styles, fonts, and variations enhances its applicability in real-world scenarios. Despite its promising results, the model has some limitations, such as difficulty with blurred images, non-horizontal orientations, and overlays of patterns, lines, or other text, which can occasionally lead to suboptimal performance. Additionally, trailing or following punctuation marks can introduce noise into the recognition process. Addressing these challenges will be a focus of future research, aiming to refine the model further, explore data augmentation techniques, optimize hyperparameters, and integrate contextual improvements for more accurate and efficient Urdu text recognition.