 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching LLMs Music Theory with In-Context Learning and Chain-of-Thought Prompting: Pedagogical Strategies for Machines
Mar 28, 2025



This study evaluates the baseline capabilities of Large Language Models (LLMs) like ChatGPT, Claude, and Gemini to learn concepts in music theory through in-context learning and chain-of-thought prompting. Using carefully designed prompts (in-context learning) and step-by-step worked examples (chain-of-thought prompting), we explore how LLMs can be taught increasingly complex material and how pedagogical strategies for human learners translate to educating machines. Performance is evaluated using questions from an official Canadian Royal Conservatory of Music (RCM) Level 6 examination, which covers a comprehensive range of topics, including interval and chord identification, key detection, cadence classification, and metrical analysis. Additionally, we evaluate the suitability of various music encoding formats for these tasks (ABC, Humdrum, MEI, MusicXML). All experiments were run both with and without contextual prompts. Results indicate that without context, ChatGPT with MEI performs the best at 52%, while with context, Claude with MEI performs the best at 75%. Future work will further refine prompts and expand to cover more advanced music theory concepts. This research contributes to the broader understanding of teaching LLMs and has applications for educators, students, and developers of AI music tools alike.
Automatic staff reconstruction within SIMSSA proect
Nov 19, 2024
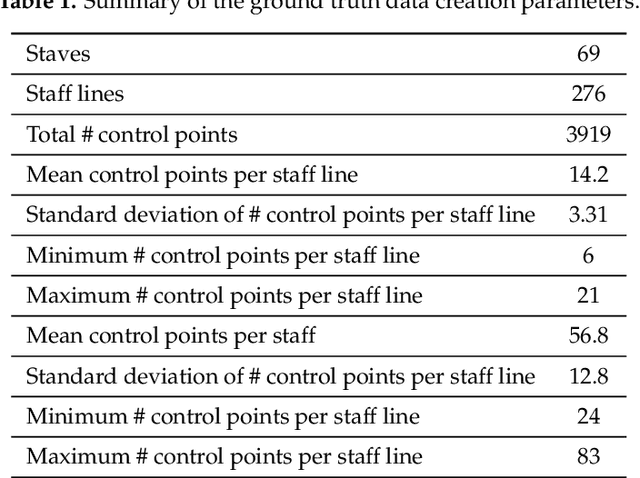
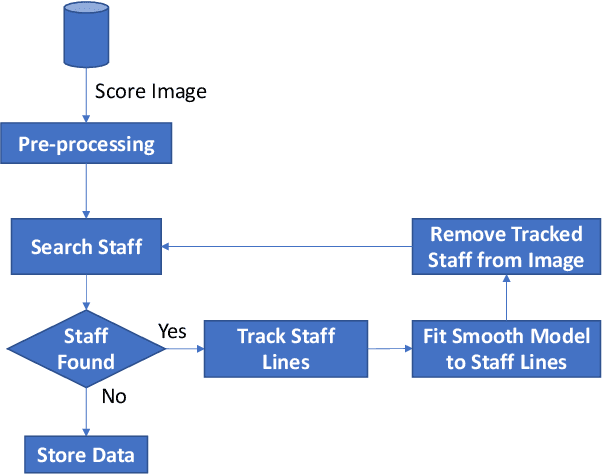

The automatic analysis of scores has been a research topic of interest for the last few decades and still is since music databases that include musical scores are currently being created to make musical content available to the public, including scores of ancient music. For the correct analysis of music elements and their interpretation, the identification of staff lines is of key importance. In this paper, a scheme to post-process the output of a previous musical object identification system is described. This system allows the reconstruction by means of detection, tracking and interpolation of the staff lines of ancient scores from the digital Salzinnes Database. The scheme developed shows a remarkable performance on the specific task it was created for.
* 15 pages