 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging End-to-End Speech Recognition with Neural Architecture Search
Dec 11, 2019
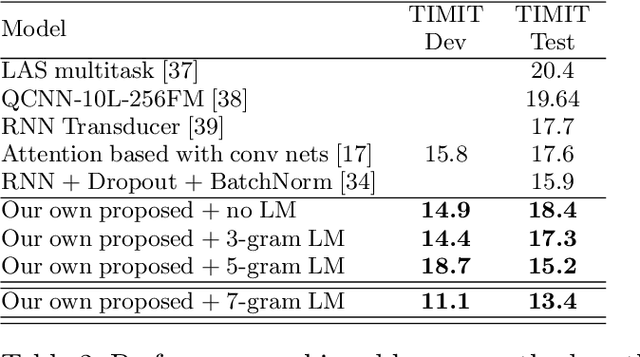

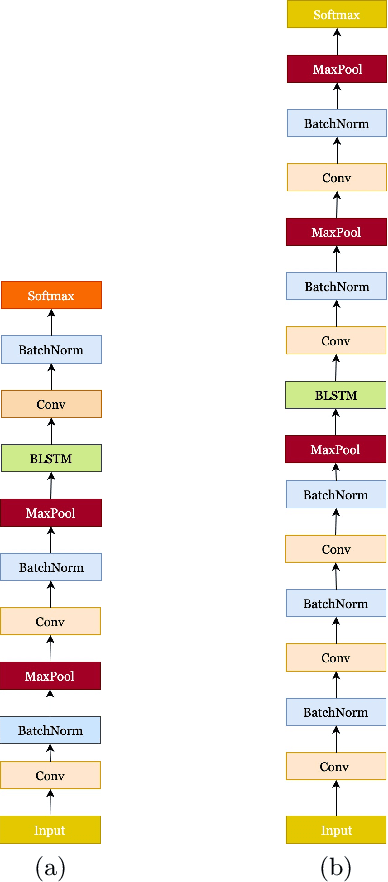
Deep neural networks (DNNs) have been demonstrated to outperform many traditional machine learning algorithms in Automatic Speech Recognition (ASR). In this paper, we show that a large improvement in the accuracy of deep speech models can be achieved with effective Neural Architecture Optimization at a very low computational cost. Phone recognition tests with the popular LibriSpeech and TIMIT benchmarks proved this fact by displaying the ability to discover and train novel candidate models within a few hours (less than a day) many times faster than the attention-based seq2seq models. Our method achieves test error of 7% Word Error Rate (WER) on the LibriSpeech corpus and 13% Phone Error Rate (PER) on the TIMIT corpus, on par with state-of-the-art results.