 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Data Dependency with Communication Cost
Apr 29, 2018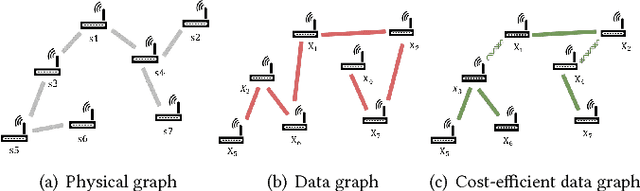
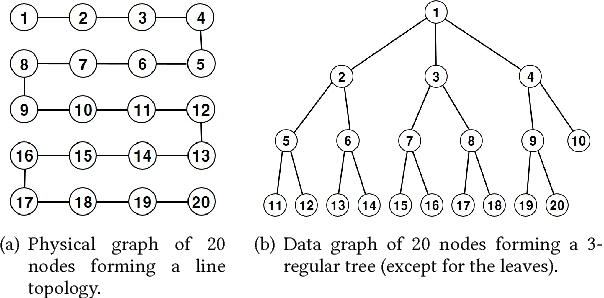
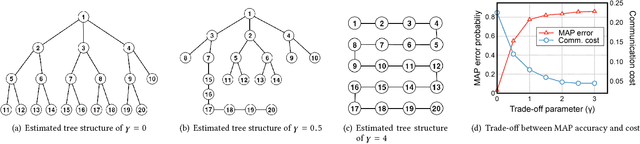
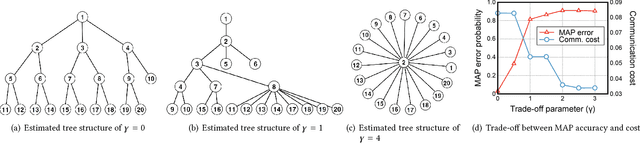
In this paper, we consider the problem of recovering a graph that represents the statistical data dependency among nodes for a set of data samples generated by nodes, which provides the basic structure to perform an inference task, such as MAP (maximum a posteriori). This problem is referred to as structure learning. When nodes are spatially separated in different locations, running an inference algorithm requires a non-negligible amount of message passing, incurring some communication cost. We inevitably have the trade-off between the accuracy of structure learning and the cost we need to pay to perform a given message-passing based inference task because the learnt edge structures of data dependency and physical connectivity graph are often highly different. In this paper, we formalize this trade-off in an optimization problem which outputs the data dependency graph that jointly considers learning accuracy and message-passing costs. We focus on a distributed MAP as the target inference task, and consider two different implementations, ASYNC-MAP and SYNC-MAP that have different message-passing mechanisms and thus different cost structures. In ASYNC- MAP, we propose a polynomial time learning algorithm that is optimal, motivated by the problem of finding a maximum weight spanning tree. In SYNC-MAP, we first prove that it is NP-hard and propose a greedy heuristic. For both implementations, we then quantify how the probability that the resulting data graphs from those learning algorithms differ from the ideal data graph decays as the number of data samples grows, using the large deviation principle, where the decaying rate is characterized by some topological structures of both original data dependency and physical connectivity graphs as well as the degree of the trade-off. We validate our theoretical findings through extensive simulations, which confirms that it has a good match.