 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Secrecy and Covert Communications (SSACC) in Mobility-Aware RIS-Aided Networks
Dec 18, 2025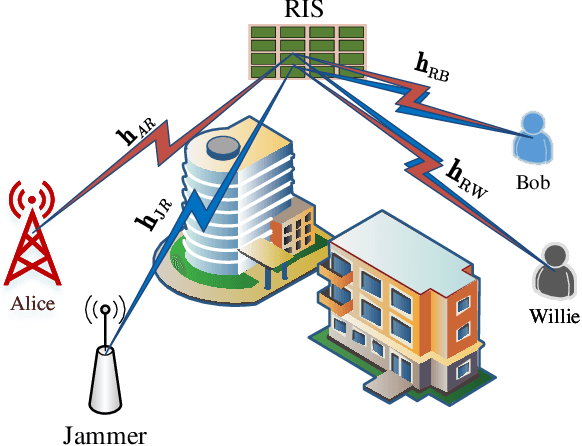
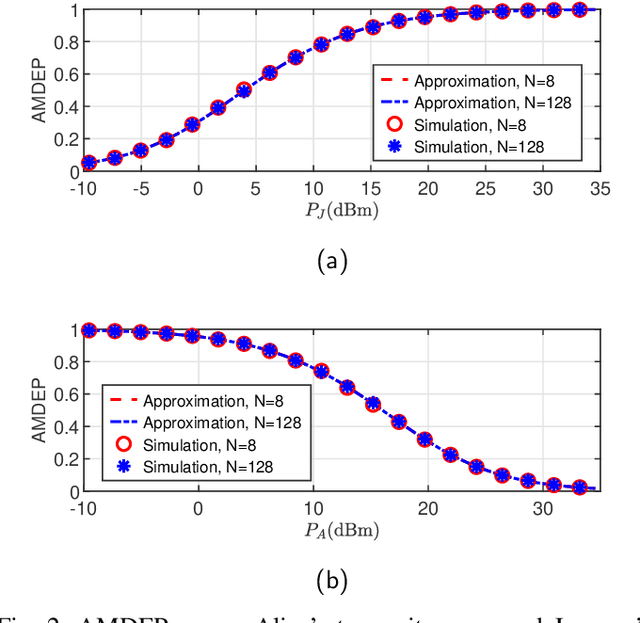
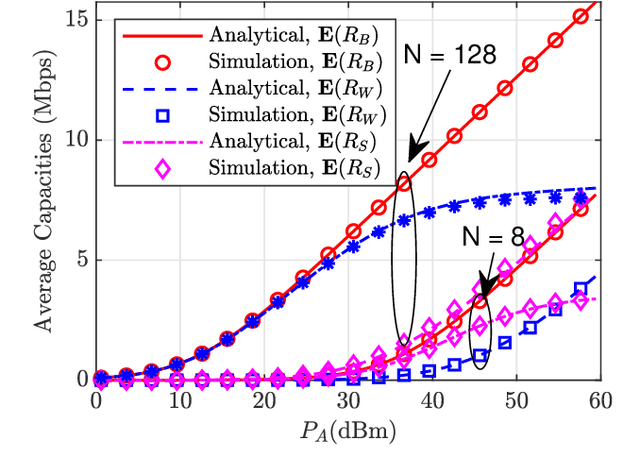
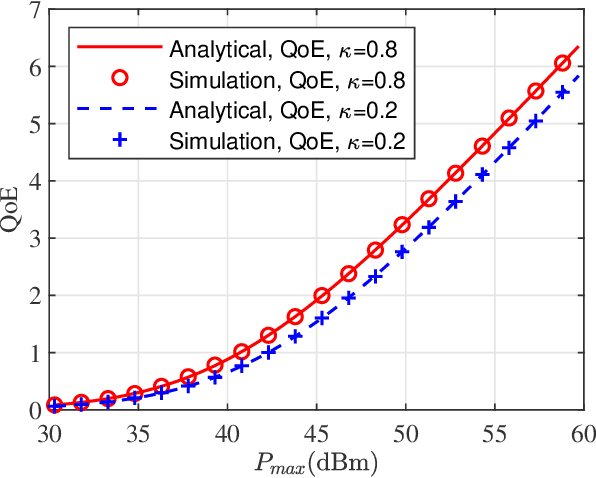
In this paper, we propose a simultaneous secrecy and covert communications (SSACC) scheme in a reconfigurable intelligent surface (RIS)-aided network with a cooperative jammer. The scheme enhances communication security by maximizing the secrecy capacity and the detection error probability (DEP). Under a worst-case scenario for covert communications, we consider that the eavesdropper can optimally adjust the detection threshold to minimize the DEP. Accordingly, we derive closedform expressions for both average minimum DEP (AMDEP) and average secrecy capacity (ASC). To balance AMDEP and ASC, we propose a new performance metric and design an algorithm based on generative diffusion models (GDM) and deep reinforcement learning (DRL). The algorithm maximizes data rates under user mobility while ensuring high AMDEP and ASC by optimizing power allocation. Simulation results demonstrate that the proposed algorithm achieves faster convergence and superior performance compared to conventional deep deterministic policy gradient (DDPG) methods, thereby validating its effectiveness in balancing security and capacity performance.
A Flexible Recursive Network for Video Stereo Matching Based on Residual Estimation
Jun 05, 2024



Due to the high similarity of disparity between consecutive frames in video sequences, the area where disparity changes is defined as the residual map, which can be calculated. Based on this, we propose RecSM, a network based on residual estimation with a flexible recursive structure for video stereo matching. The RecSM network accelerates stereo matching using a Multi-scale Residual Estimation Module (MREM), which employs the temporal context as a reference and rapidly calculates the disparity for the current frame by computing only the residual values between the current and previous frames. To further reduce the error of estimated disparities, we use the Disparity Optimization Module (DOM) and Temporal Attention Module (TAM) to enforce constraints between each module, and together with MREM, form a flexible Stackable Computation Structure (SCS), which allows for the design of different numbers of SCS based on practical scenarios. Experimental results demonstrate that with a stack count of 3, RecSM achieves a 4x speed improvement compared to ACVNet, running at 0.054 seconds based on one NVIDIA RTX 2080TI GPU, with an accuracy decrease of only 0.7%. Code is available at https://github.com/Y0uchenZ/RecSM.
Histopathology Based AI Model Predicts Anti-Angiogenic Therapy Response in Renal Cancer Clinical Trial
May 28, 2024



Predictive biomarkers of treatment response are lacking for metastatic clear cell renal cell carcinoma (ccRCC), a tumor type that is treated with angiogenesis inhibitors, immune checkpoint inhibitors, mTOR inhibitors and a HIF2 inhibitor. The Angioscore, an RNA-based quantification of angiogenesis, is arguably the best candidate to predict anti-angiogenic (AA) response. However, the clinical adoption of transcriptomic assays faces several challenges including standardization, time delay, and high cost. Further, ccRCC tumors are highly heterogenous, and sampling multiple areas for sequencing is impractical. Here we present a novel deep learning (DL) approach to predict the Angioscore from ubiquitous histopathology slides. To overcome the lack of interpretability, one of the biggest limitations of typical DL models, our model produces a visual vascular network which is the basis of the model's prediction. To test its reliability, we applied this model to multiple cohorts including a clinical trial dataset. Our model accurately predicts the RNA-based Angioscore on multiple independent cohorts (spearman correlations of 0.77 and 0.73). Further, the predictions help unravel meaningful biology such as association of angiogenesis with grade, stage, and driver mutation status. Finally, we find our model can predict response to AA therapy, in both a real-world cohort and the IMmotion150 clinical trial. The predictive power of our model vastly exceeds that of CD31, a marker of vasculature, and nearly rivals the performance (c-index 0.66 vs 0.67) of the ground truth RNA-based Angioscore at a fraction of the cost. By providing a robust yet interpretable prediction of the Angioscore from histopathology slides alone, our approach offers insights into angiogenesis biology and AA treatment response.
PAANet:Visual Perception based Four-stage Framework for Salient Object Detection using High-order Contrast Operator
Nov 16, 2022



It is believed that human vision system (HVS) consists of pre-attentive process and attention process when performing salient object detection (SOD). Based on this fact, we propose a four-stage framework for SOD, in which the first two stages match the \textbf{P}re-\textbf{A}ttentive process consisting of general feature extraction (GFE) and feature preprocessing (FP), and the last two stages are corresponding to \textbf{A}ttention process containing saliency feature extraction (SFE) and the feature aggregation (FA), namely \textbf{PAANet}. According to the pre-attentive process, the GFE stage applies the fully-trained backbone and needs no further finetuning for different datasets. This modification can greatly increase the training speed. The FP stage plays the role of finetuning but works more efficiently because of its simpler structure and fewer parameters. Moreover, in SFE stage we design for saliency feature extraction a novel contrast operator, which works more semantically in contrast with the traditional convolution operator when extracting the interactive information between the foreground and its surroundings. Interestingly, this contrast operator can be cascaded to form a deeper structure and extract higher-order saliency more effective for complex scene. Comparative experiments with the state-of-the-art methods on 5 datasets demonstrate the effectiveness of our framework.