 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSesameBERT: Attention for Anywhere
Oct 08, 2019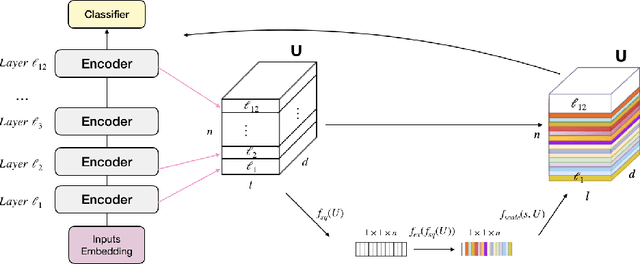
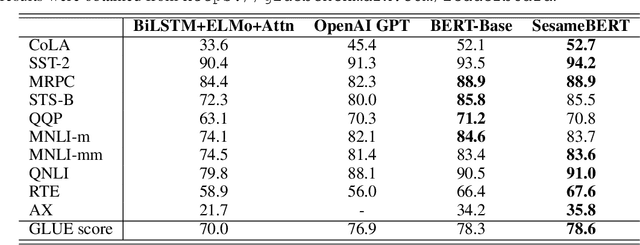
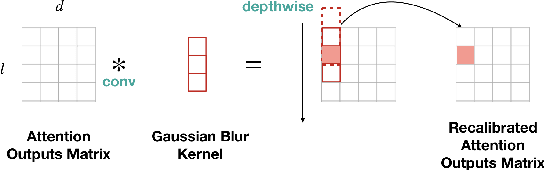
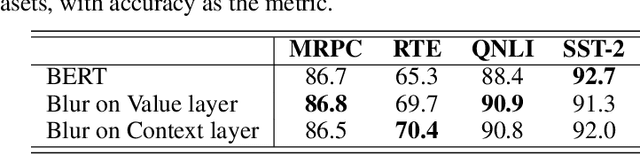
Fine-tuning with pre-trained models has achieved exceptional results for many language tasks. In this study, we focused on one such self-attention network model, namely BERT, which has performed well in terms of stacking layers across diverse language-understanding benchmarks. However, in many downstream tasks, information between layers is ignored by BERT for fine-tuning. In addition, although self-attention networks are well-known for their ability to capture global dependencies, room for improvement remains in terms of emphasizing the importance of local contexts. In light of these advantages and disadvantages, this paper proposes SesameBERT, a generalized fine-tuning method that (1) enables the extraction of global information among all layers through Squeeze and Excitation and (2) enriches local information by capturing neighboring contexts via Gaussian blurring. Furthermore, we demonstrated the effectiveness of our approach in the HANS dataset, which is used to determine whether models have adopted shallow heuristics instead of learning underlying generalizations. The experiments revealed that SesameBERT outperformed BERT with respect to GLUE benchmark and the HANS evaluation set.