 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Foundational Large Language Models Assist with Conducting Pharmaceuticals Manufacturing Investigations?
Apr 24, 2024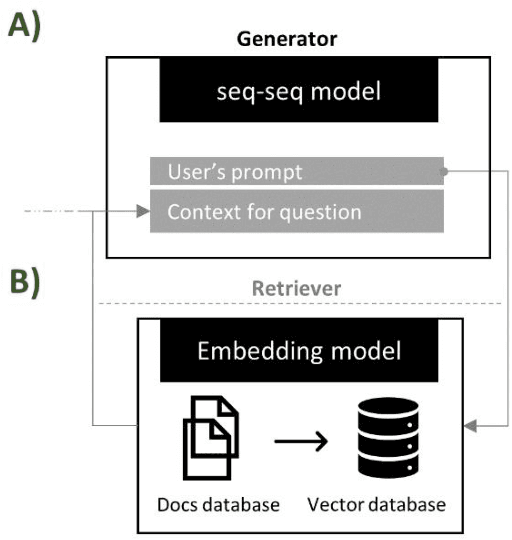

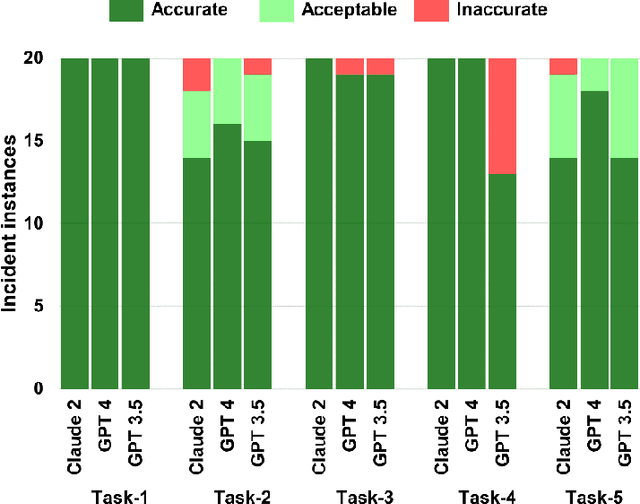
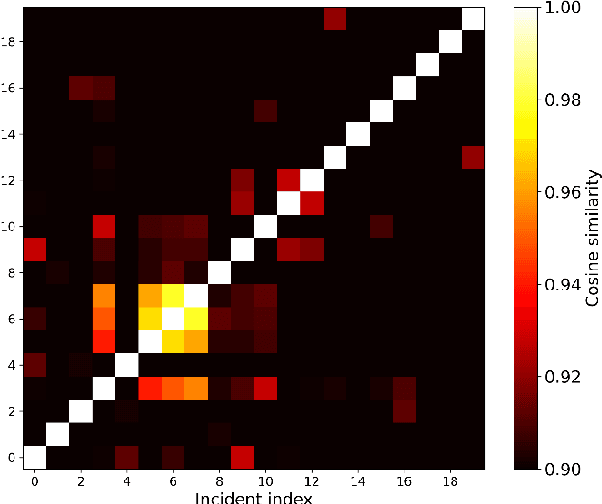
General purpose Large Language Models (LLM) such as the Generative Pretrained Transformer (GPT) and Large Language Model Meta AI (LLaMA) have attracted much attention in recent years. There is strong evidence that these models can perform remarkably well in various natural language processing tasks. However, how to leverage them to approach domain-specific use cases and drive value remains an open question. In this work, we focus on a specific use case, pharmaceutical manufacturing investigations, and propose that leveraging historical records of manufacturing incidents and deviations in an organization can be beneficial for addressing and closing new cases, or de-risking new manufacturing campaigns. Using a small but diverse dataset of real manufacturing deviations selected from different product lines, we evaluate and quantify the power of three general purpose LLMs (GPT-3.5, GPT-4, and Claude-2) in performing tasks related to the above goal. In particular, (1) the ability of LLMs in automating the process of extracting specific information such as root cause of a case from unstructured data, as well as (2) the possibility of identifying similar or related deviations by performing semantic search on the database of historical records are examined. While our results point to the high accuracy of GPT-4 and Claude-2 in the information extraction task, we discuss cases of complex interplay between the apparent reasoning and hallucination behavior of LLMs as a risk factor. Furthermore, we show that semantic search on vector embedding of deviation descriptions can be used to identify similar records, such as those with a similar type of defect, with a high level of accuracy. We discuss further improvements to enhance the accuracy of similar record identification.