 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embeddings Are Capable of Capturing Rhythmic Similarity of Words
Apr 14, 2022



Word embedding systems such as Word2Vec and GloVe are well-known in deep learning approaches to NLP. This is largely due to their ability to capture semantic relationships between words. In this work we investigated their usefulness in capturing rhythmic similarity of words instead. The results show that vectors these embeddings assign to rhyming words are more similar to each other, compared to the other words. It is also revealed that GloVe performs relatively better than Word2Vec in this regard. We also proposed a first of its kind metric for quantifying rhythmic similarity of a pair of words.
Features in Extractive Supervised Single-document Summarization: Case of Persian News
Sep 09, 2019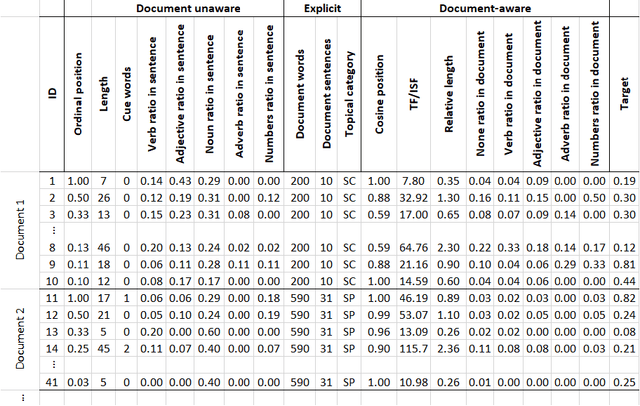

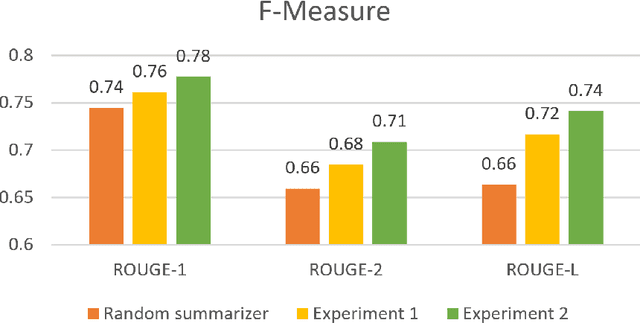
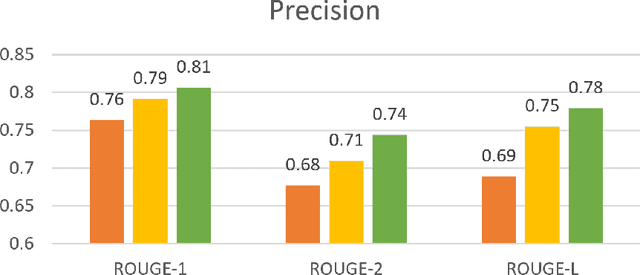
Text summarization has been one of the most challenging areas of research in NLP. Much effort has been made to overcome this challenge by using either the abstractive or extractive methods. Extractive methods are more popular, due to their simplicity compared with the more elaborate abstractive methods. In extractive approaches, the system will not generate sentences. Instead, it learns how to score sentences within the text by using some textual features and subsequently selecting those with the highest-rank. Therefore, the core objective is ranking and it highly depends on the document. This dependency has been unnoticed by many state-of-the-art solutions. In this work, the features of the document are integrated into vectors of every sentence. In this way, the system becomes informed about the context, increases the precision of the learned model and consequently produces comprehensive and brief summaries.