 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning linear acyclic causal model including Gaussian noise using ancestral relationships
Aug 31, 2024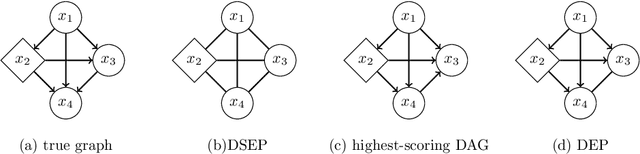
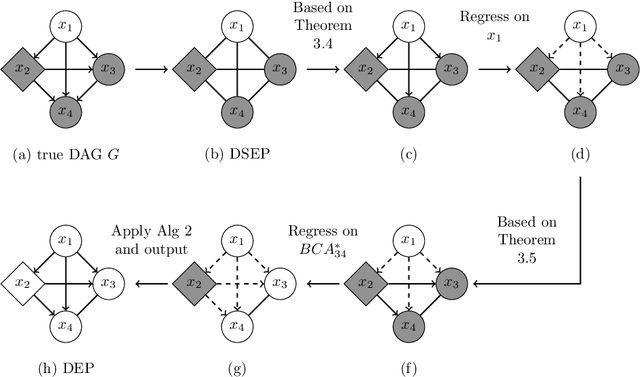
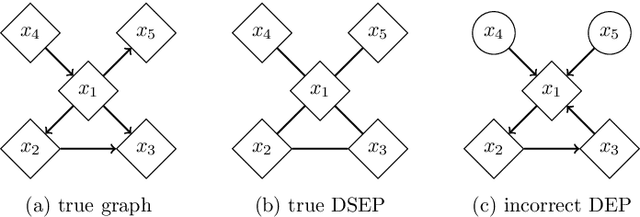
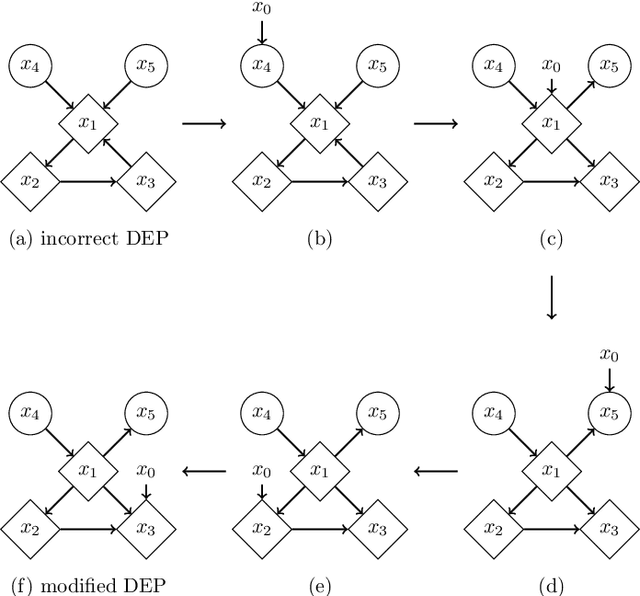
This paper discusses algorithms for learning causal DAGs. The PC algorithm makes no assumptions other than the faithfulness to the causal model and can identify only up to the Markov equivalence class. LiNGAM assumes linearity and continuous non-Gaussian disturbances for the causal model, and the causal DAG defining LiNGAM is shown to be fully identifiable. The PC-LiNGAM, a hybrid of the PC algorithm and LiNGAM, can identify up to the distribution-equivalence pattern of a linear causal model, even in the presence of Gaussian disturbances. However, in the worst case, the PC-LiNGAM has factorial time complexity for the number of variables. In this paper, we propose an algorithm for learning the distribution-equivalence patterns of a linear causal model with a lower time complexity than PC-LiNGAM, using the causal ancestor finding algorithm in Maeda and Shimizu, which is generalized to account for Gaussian disturbances.
Learning causal graphs using variable grouping according to ancestral relationship
Mar 21, 2024Several causal discovery algorithms have been proposed. However, when the sample size is small relative to the number of variables, the accuracy of estimating causal graphs using existing methods decreases. And some methods are not feasible when the sample size is smaller than the number of variables. To circumvent these problems, some researchers proposed causal structure learning algorithms using divide-and-conquer approaches. For learning the entire causal graph, the approaches first split variables into several subsets according to the conditional independence relationships among the variables, then apply a conventional causal discovery algorithm to each subset and merge the estimated results. Since the divide-and-conquer approach reduces the number of variables to which a causal structure learning algorithm is applied, it is expected to improve the estimation accuracy of causal graphs, especially when the sample size is small relative to the number of variables and the model is sparse. However, existing methods are either computationally expensive or do not provide sufficient accuracy when the sample size is small. This paper proposes a new algorithm for grouping variables based the ancestral relationships among the variables, under the LiNGAM assumption, where the causal relationships are linear, and the mutually independent noise are distributed as continuous non-Gaussian distributions. We call the proposed algorithm CAG. The time complexity of the ancestor finding in CAG is shown to be cubic to the number of variables. Extensive computer experiments confirm that the proposed method outperforms the original DirectLiNGAM without grouping variables and other divide-and-conquer approaches not only in estimation accuracy but also in computation time when the sample size is small relative to the number of variables and the model is sparse.