 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhishing Website Detection through Multi-Model Analysis of HTML Content
Jan 09, 2024The way we communicate and work has changed significantly with the rise of the Internet. While it has opened up new opportunities, it has also brought about an increase in cyber threats. One common and serious threat is phishing, where cybercriminals employ deceptive methods to steal sensitive information.This study addresses the pressing issue of phishing by introducing an advanced detection model that meticulously focuses on HTML content. Our proposed approach integrates a specialized Multi-Layer Perceptron (MLP) model for structured tabular data and two pretrained Natural Language Processing (NLP) models for analyzing textual features such as page titles and content. The embeddings from these models are harmoniously combined through a novel fusion process. The resulting fused embeddings are then input into a linear classifier. Recognizing the scarcity of recent datasets for comprehensive phishing research, our contribution extends to the creation of an up-to-date dataset, which we openly share with the community. The dataset is meticulously curated to reflect real-life phishing conditions, ensuring relevance and applicability. The research findings highlight the effectiveness of the proposed approach, with the CANINE demonstrating superior performance in analyzing page titles and the RoBERTa excelling in evaluating page content. The fusion of two NLP and one MLP model,termed MultiText-LP, achieves impressive results, yielding a 96.80 F1 score and a 97.18 accuracy score on our research dataset. Furthermore, our approach outperforms existing methods on the CatchPhish HTML dataset, showcasing its efficacies.
SecureReg: A Combined Framework for Proactively Exposing Malicious Domain Name Registrations
Jan 06, 2024Rising cyber threats, with miscreants registering thousands of new domains daily for Internet-scale attacks like spam, phishing, and drive-by downloads, emphasize the need for innovative detection methods. This paper introduces a cutting-edge approach for identifying suspicious domains at the onset of the registration process. The accompanying data pipeline generates crucial features by comparing new domains to registered domains,emphasizing the crucial similarity score. Leveraging a novel combination of Natural Language Processing (NLP) techniques, including a pretrained Canine model, and Multilayer Perceptron (MLP) models, our system analyzes semantic and numerical attributes, providing a robust solution for early threat detection. This integrated approach significantly reduces the window of vulnerability, fortifying defenses against potential threats. The findings demonstrate the effectiveness of the integrated approach and contribute to the ongoing efforts in developing proactive strategies to mitigate the risks associated with illicit online activities through the early identification of suspicious domain registrations.
An Ensemble of Pre-trained Transformer Models For Imbalanced Multiclass Malware Classification
Jan 02, 2022
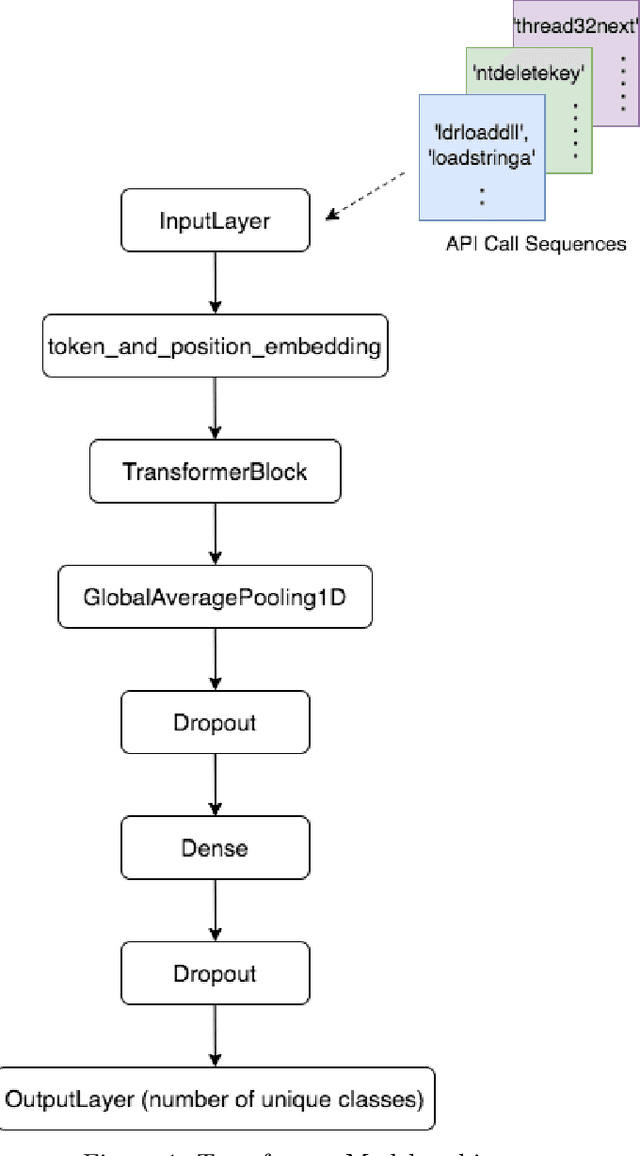


Classification of malware families is crucial for a comprehensive understanding of how they can infect devices, computers, or systems. Thus, malware identification enables security researchers and incident responders to take precautions against malware and accelerate mitigation. API call sequences made by malware are widely utilized features by machine and deep learning models for malware classification as these sequences represent the behavior of malware. However, traditional machine and deep learning models remain incapable of capturing sequence relationships between API calls. On the other hand, the transformer-based models process sequences as a whole and learn relationships between API calls due to multi-head attention mechanisms and positional embeddings. Our experiments demonstrate that the transformer model with one transformer block layer surpassed the widely used base architecture, LSTM. Moreover, BERT or CANINE, pre-trained transformer models, outperformed in classifying highly imbalanced malware families according to evaluation metrics, F1-score, and AUC score. Furthermore, the proposed bagging-based random transformer forest (RTF), an ensemble of BERT or CANINE, has reached the state-of-the-art evaluation scores on three out of four datasets, particularly state-of-the-art F1-score of 0.6149 on one of the commonly used benchmark dataset.
New Datasets for Dynamic Malware Classification
Nov 30, 2021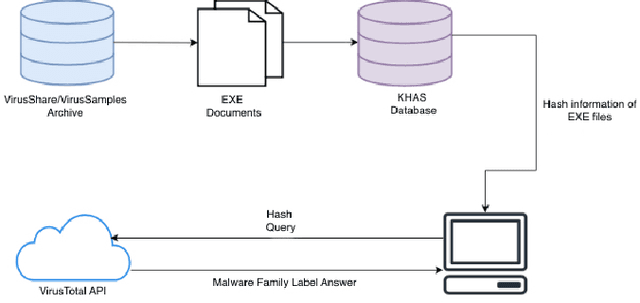


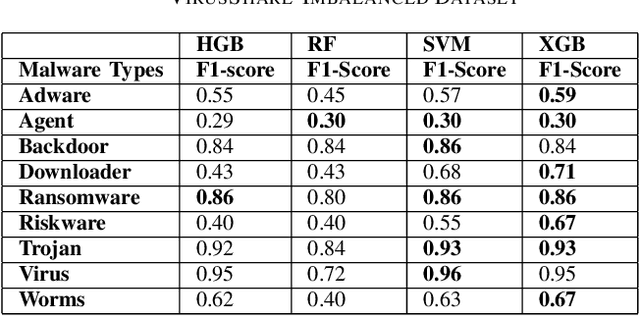
Nowadays, malware and malware incidents are increasing daily, even with various anti-viruses systems and malware detection or classification methodologies. Many static, dynamic, and hybrid techniques have been presented to detect malware and classify them into malware families. Dynamic and hybrid malware classification methods have advantages over static malware classification methods by being highly efficient. Since it is difficult to mask malware behavior while executing than its underlying code in static malware classification, machine learning techniques have been the main focus of the security experts to detect malware and determine their families dynamically. The rapid increase of malware also brings the necessity of recent and updated datasets of malicious software. We introduce two new, updated datasets in this work: One with 9,795 samples obtained and compiled from VirusSamples and the one with 14,616 samples from VirusShare. This paper also analyzes multi-class malware classification performance of the balanced and imbalanced version of these two datasets by using Histogram-based gradient boosting, Random Forest, Support Vector Machine, and XGBoost models with API call-based dynamic malware classification. Results show that Support Vector Machine, achieves the highest score of 94% in the imbalanced VirusSample dataset, whereas the same model has 91% accuracy in the balanced VirusSample dataset. While XGBoost, one of the most common gradient boosting-based models, achieves the highest score of 90% and 80%.in both versions of the VirusShare dataset. This paper also presents the baseline results of VirusShare and VirusSample datasets by using the four most widely known machine learning techniques in dynamic malware classification literature. We believe that these two datasets and baseline results enable researchers in this field to test and validate their methods and approaches.
Random CapsNet Forest Model for Imbalanced Malware Type Classification Task
Dec 20, 2019



Behavior of a malware varies with respect to malware types. Therefore,knowing type of a malware affects strategies of system protection softwares. Many malware type classification models empowered by machine and deep learning achieve superior accuracies to predict malware types.Machine learning based models need to do heavy feature engineering and feature engineering is dominantly effecting performance of models.On the other hand, deep learning based models require less feature engineering than machine learning based models. However, traditional deep learning architectures and components cause very complex and data sensitive models. Capsule network architecture minimizes this complexity and data sensitivity unlike classical convolutional neural network architectures. This paper proposes an ensemble capsule network model based on bootstrap aggregating technique. The proposed method are tested on two malware datasets, whose the-state-of-the-art results are well-known.