 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Emotions in Abstract Art: Cognitive Plausibility of CLIP in Recognizing Color-Emotion Associations
May 10, 2024
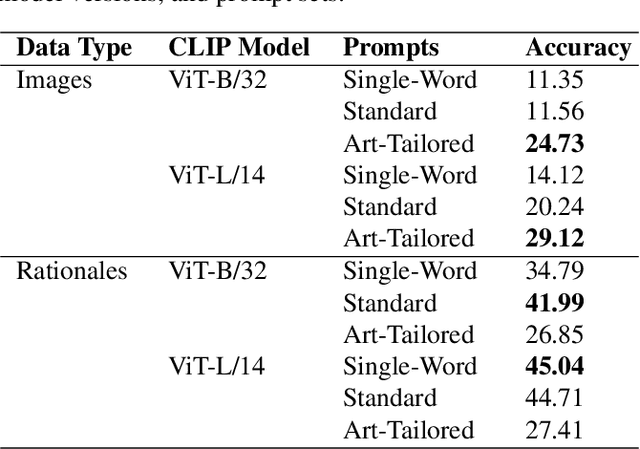
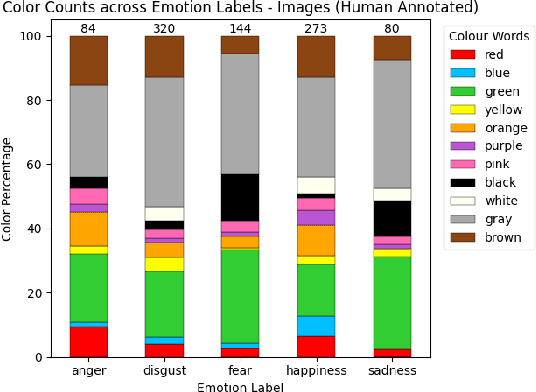
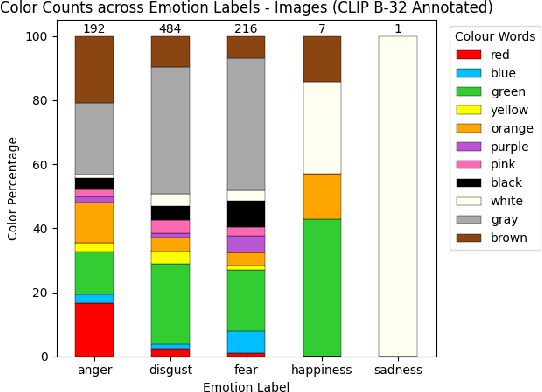
This study investigates the cognitive plausibility of a pretrained multimodal model, CLIP, in recognizing emotions evoked by abstract visual art. We employ a dataset comprising images with associated emotion labels and textual rationales of these labels provided by human annotators. We perform linguistic analyses of rationales, zero-shot emotion classification of images and rationales, apply similarity-based prediction of emotion, and investigate color-emotion associations. The relatively low, yet above baseline, accuracy in recognizing emotion for abstract images and rationales suggests that CLIP decodes emotional complexities in a manner not well aligned with human cognitive processes. Furthermore, we explore color-emotion interactions in images and rationales. Expected color-emotion associations, such as red relating to anger, are identified in images and texts annotated with emotion labels by both humans and CLIP, with the latter showing even stronger interactions. Our results highlight the disparity between human processing and machine processing when connecting image features and emotions.