 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Right Expansion-ordering Heuristics for Satisfiability Testing in OWL Reasoners
Apr 20, 2019
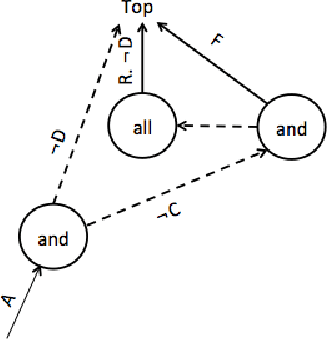
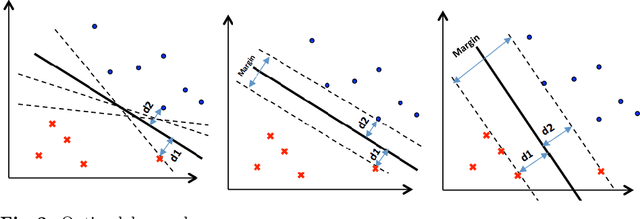
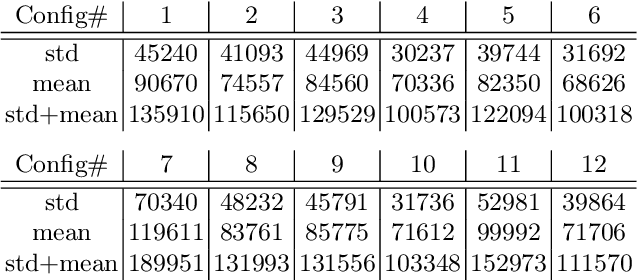
Web Ontology Language (OWL) reasoners are used to infer new logical relations from ontologies. While inferring new facts, these reasoners can be further optimized, e.g., by properly ordering disjuncts in disjunction expressions of ontologies for satisfiability testing of concepts. Different expansion-ordering heuristics have been developed for this purpose. The built-in heuristics in these reasoners determine the order for branches in search trees while each heuristic choice causes different effects for various ontologies depending on the ontologies' syntactic structure and probably other features as well. A learning-based approach that takes into account the features aims to select an appropriate expansion-ordering heuristic for each ontology. The proper choice is expected to accelerate the reasoning process for the reasoners. In this paper, the effect of our methodology is investigated on a well-known reasoner that is JFact. Our experiments show the average speedup by a factor of one to two orders of magnitude for satisfiability testing after applying learning methodology for selecting the right expansion-ordering heuristics.
Optimizing Heuristics for Tableau-based OWL Reasoners
Oct 24, 2018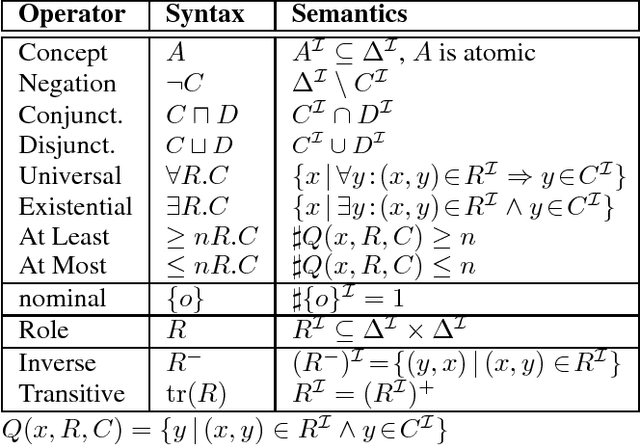

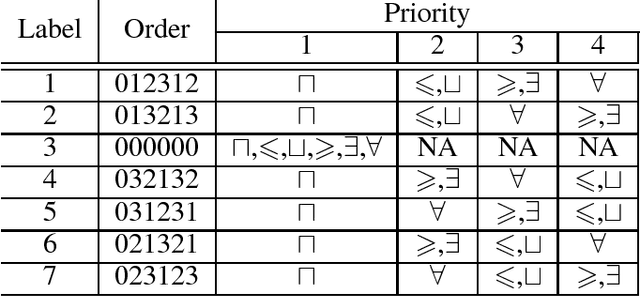
Optimization techniques play a significant role in improving description logic reasoners covering the Web Ontology Language (OWL). These techniques are essential to speed up these reasoners. Many of the optimization techniques are based on heuristic choices. Optimal heuristic selection makes these techniques more effective. The FaCT++ OWL reasoner and its Java version JFact implement an optimization technique called ToDo list which is a substitute for a traditional top-down approach in tableau-based reasoners. The ToDo list mechanism allows one to arrange the order of applying different rules by giving each a priority. Compared to a top-down approach, the ToDo list technique has a better control over the application of expansion rules. Learning the proper heuristic order for applying rules in ToDo lis} will have a great impact on reasoning speed. We use a binary SVM technique to build our learning model. The model can help to choose ontology-specific order sets to speed up OWL reasoning. On average, our learning approach tested with 40 selected ontologies achieves a speedup of two orders of magnitude when compared to the worst rule ordering choice.
Predicting health inspection results from online restaurant reviews
Mar 17, 2016

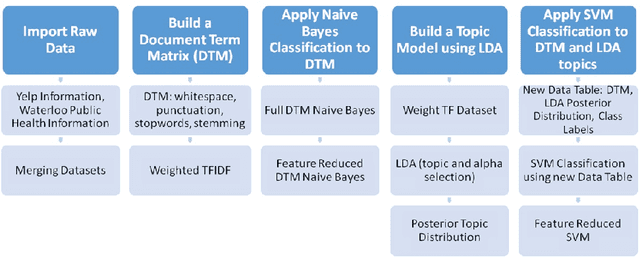
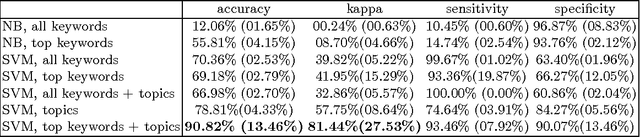
Informatics around public health are increasingly shifting from the professional to the public spheres. In this work, we apply linguistic analytics to restaurant reviews, from Yelp, in order to automatically predict official health inspection reports. We consider two types of feature sets, i.e., keyword detection and topic model features, and use these in several classification methods. Our empirical analysis shows that these extracted features can predict public health inspection reports with over 90% accuracy using simple support vector machines.
Learning measures of semi-additive behaviour
Dec 09, 2015

In business analytics, measure values, such as sales numbers or volumes of cargo transported, are often summed along values of one or more corresponding categories, such as time or shipping container. However, not every measure should be added by default (e.g., one might more typically want a mean over the heights of a set of people); similarly, some measures should only be summed within certain constraints (e.g., population measures need not be summed over years). In systems such as Watson Analytics, the exact additive behaviour of a measure is often determined by a human expert. In this work, we propose a small set of features for this issue. We use these features in a case-based reasoning approach, where the system suggests an aggregation behaviour, with 86% accuracy in our collected dataset.