 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperPos-Prompt: Enhancing Soft Prompt Tuning of Language Models with Superposition of Multi Token Embeddings
Jun 07, 2024



Soft prompt tuning techniques have recently gained traction as an effective strategy for the parameter-efficient tuning of pretrained language models, particularly minimizing the required adjustment of model parameters. Despite their growing use, achieving optimal tuning with soft prompts, especially for smaller datasets, remains a substantial challenge. This study makes two contributions in this domain: (i) we introduce SuperPos-Prompt, a new reparameterization technique employing the superposition of multiple pretrained vocabulary embeddings to improve the learning of soft prompts. Our experiments across several GLUE and SuperGLUE benchmarks consistently highlight SuperPos-Prompt's superiority over Residual Prompt tuning, exhibiting an average score increase of $+6.4$ in T5-Small and $+5.0$ in T5-Base along with a faster convergence. Remarkably, SuperPos-Prompt occasionally outperforms even full fine-tuning methods. (ii) Additionally, we demonstrate enhanced performance and rapid convergence by omitting dropouts from the frozen network, yielding consistent improvements across various scenarios and tuning methods.
Crowd Labeling: a survey
Sep 03, 2014

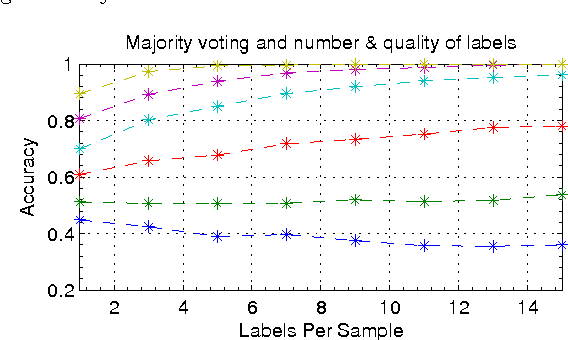
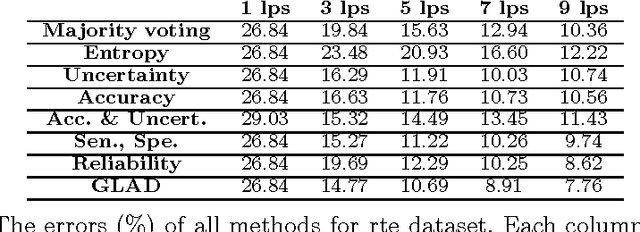
Recently, there has been a burst in the number of research projects on human computation via crowdsourcing. Multiple choice (or labeling) questions could be referred to as a common type of problem which is solved by this approach. As an application, crowd labeling is applied to find true labels for large machine learning datasets. Since crowds are not necessarily experts, the labels they provide are rather noisy and erroneous. This challenge is usually resolved by collecting multiple labels for each sample, and then aggregating them to estimate the true label. Although the mechanism leads to high-quality labels, it is not actually cost-effective. As a result, efforts are currently made to maximize the accuracy in estimating true labels, while fixing the number of acquired labels. This paper surveys methods to aggregate redundant crowd labels in order to estimate unknown true labels. It presents a unified statistical latent model where the differences among popular methods in the field correspond to different choices for the parameters of the model. Afterwards, algorithms to make inference on these models will be surveyed. Moreover, adaptive methods which iteratively collect labels based on the previously collected labels and estimated models will be discussed. In addition, this paper compares the distinguished methods, and provides guidelines for future work required to address the current open issues.