 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Detection of Adversarial Examples with Model Explanations
Jul 22, 2021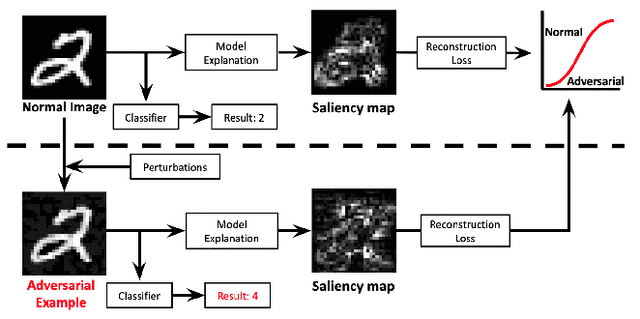


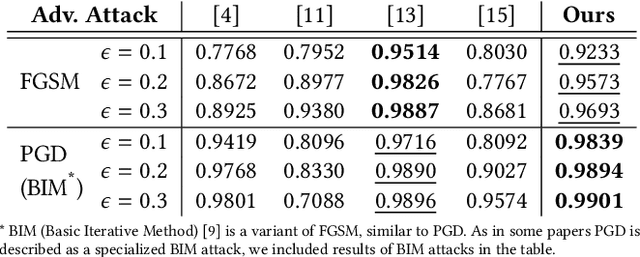
Deep Neural Networks (DNNs) have shown remarkable performance in a diverse range of machine learning applications. However, it is widely known that DNNs are vulnerable to simple adversarial perturbations, which causes the model to incorrectly classify inputs. In this paper, we propose a simple yet effective method to detect adversarial examples, using methods developed to explain the model's behavior. Our key observation is that adding small, humanly imperceptible perturbations can lead to drastic changes in the model explanations, resulting in unusual or irregular forms of explanations. From this insight, we propose an unsupervised detection of adversarial examples using reconstructor networks trained only on model explanations of benign examples. Our evaluations with MNIST handwritten dataset show that our method is capable of detecting adversarial examples generated by the state-of-the-art algorithms with high confidence. To the best of our knowledge, this work is the first in suggesting unsupervised defense method using model explanations.