 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONAH: Multi-Modal Narratives for Humans to analyze conversations
Jan 20, 2021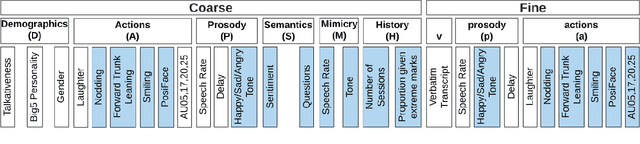
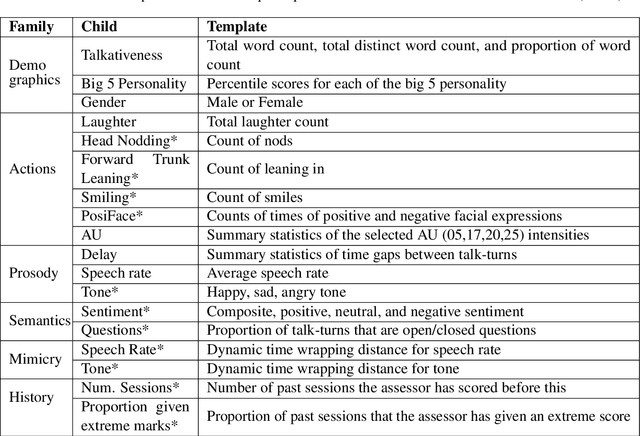
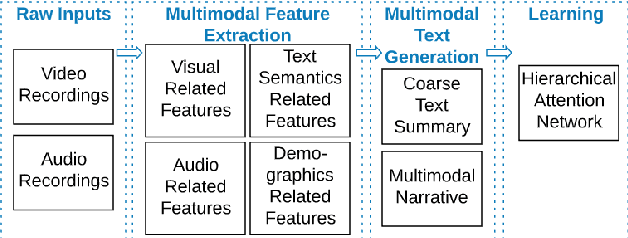
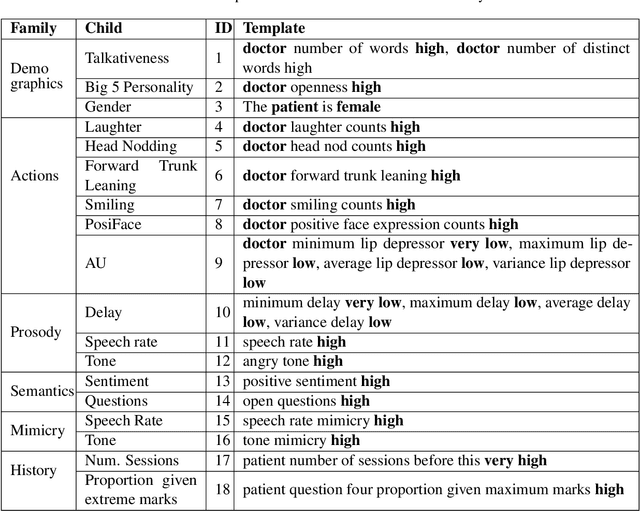
In conversational analyses, humans manually weave multimodal information into the transcripts, which is significantly time-consuming. We introduce a system that automatically expands the verbatim transcripts of video-recorded conversations using multimodal data streams. This system uses a set of preprocessing rules to weave multimodal annotations into the verbatim transcripts and promote interpretability. Our feature engineering contributions are two-fold: firstly, we identify the range of multimodal features relevant to detect rapport-building; secondly, we expand the range of multimodal annotations and show that the expansion leads to statistically significant improvements in detecting rapport-building.
Detecting depression in dyadic conversations with multimodal narratives and visualizations
Jan 27, 2020


Conversations contain a wide spectrum of multimodal information that gives us hints about the emotions and moods of the speaker. In this paper, we developed a system that supports humans to analyze conversations. Our main contribution is the identification of appropriate multimodal features and the integration of such features into verbatim conversation transcripts. We demonstrate the ability of our system to take in a wide range of multimodal information and automatically generated a prediction score for the depression state of the individual. Our experiments showed that this approach yielded better performance than the baseline model. Furthermore, the multimodal narrative approach makes it easy to integrate learnings from other disciplines, such as conversational analysis and psychology. Lastly, this interdisciplinary and automated approach is a step towards emulating how practitioners record the course of treatment as well as emulating how conversational analysts have been analyzing conversations by hand.
* 12 pages