 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Data Analytics is Enough? The ROI of Machine Learning Classification and its Application to Requirements Dependency Classification
Sep 28, 2021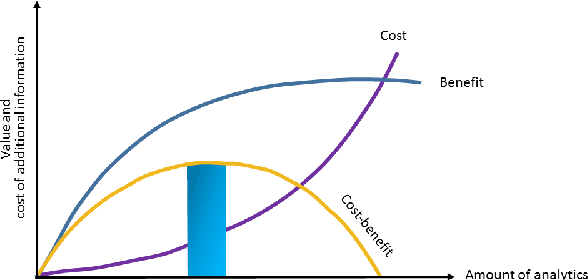
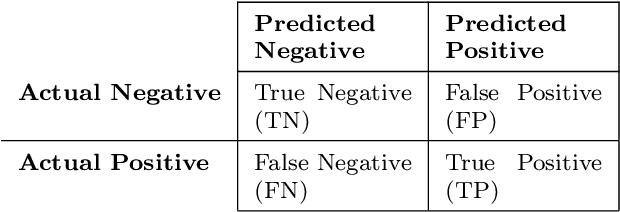
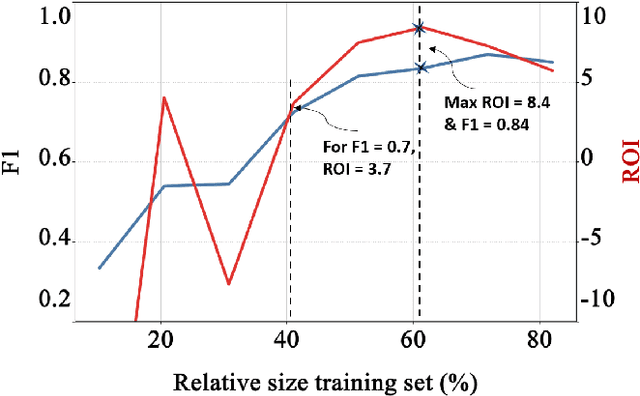
Machine Learning (ML) can substantially improve the efficiency and effectiveness of organizations and is widely used for different purposes within Software Engineering. However, the selection and implementation of ML techniques rely almost exclusively on accuracy criteria. Thus, for organizations wishing to realize the benefits of ML investments, this narrow approach ignores crucial considerations around the anticipated costs of the ML activities across the ML lifecycle, while failing to account for the benefits that are likely to accrue from the proposed activity. We present findings for an approach that addresses this gap by enhancing the accuracy criterion with return on investment (ROI) considerations. Specifically, we analyze the performance of the two state-of-the-art ML techniques: Random Forest and Bidirectional Encoder Representations from Transformers (BERT), based on accuracy and ROI for two publicly available data sets. Specifically, we compare decision-making on requirements dependency extraction (i) exclusively based on accuracy and (ii) extended to include ROI analysis. As a result, we propose recommendations for selecting ML classification techniques based on the degree of training data used. Our findings indicate that considering ROI as additional criteria can drastically influence ML selection when compared to decisions based on accuracy as the sole criterion
Beyond Accuracy: ROI-driven Data Analytics of Empirical Data
Sep 14, 2020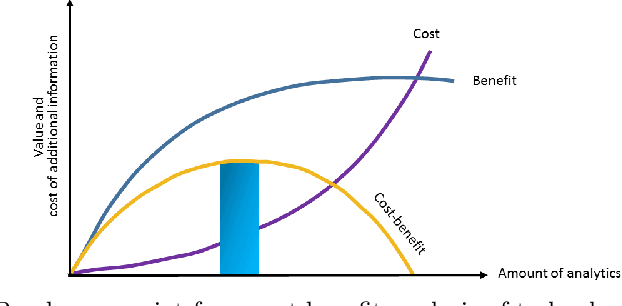
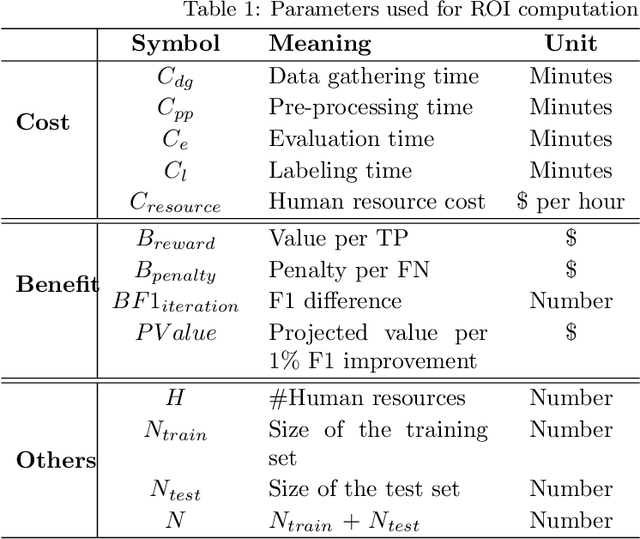
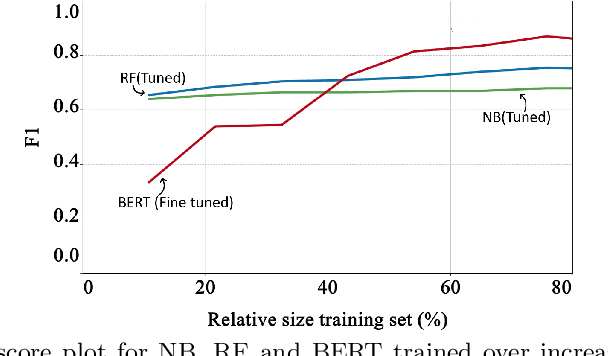
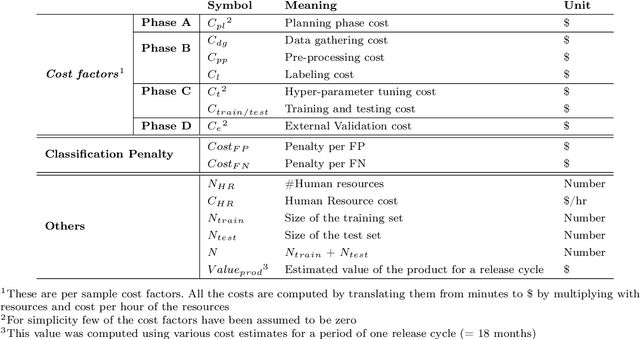
This vision paper demonstrates that it is crucial to consider Return-on-Investment (ROI) when performing Data Analytics. Decisions on "How much analytics is needed"? are hard to answer. ROI could guide for decision support on the What?, How?, and How Much? analytics for a given problem. Method: The proposed conceptual framework is validated through two empirical studies that focus on requirements dependencies extraction in the Mozilla Firefox project. The two case studies are (i) Evaluation of fine-tuned BERT against Naive Bayes and Random Forest machine learners for binary dependency classification and (ii) Active Learning against passive Learning (random sampling) for REQUIRES dependency extraction. For both the cases, their analysis investment (cost) is estimated, and the achievable benefit from DA is predicted, to determine a break-even point of the investigation. Results: For the first study, fine-tuned BERT performed superior to the Random Forest, provided that more than 40% of training data is available. For the second, Active Learning achieved higher F1 accuracy within fewer iterations and higher ROI compared to Baseline (Random sampling based RF classifier). In both the studies, estimate on, How much analysis likely would pay off for the invested efforts?, was indicated by the break-even point. Conclusions: Decisions for the depth and breadth of DA of empirical data should not be made solely based on the accuracy measures. Since ROI-driven Data Analytics provides a simple yet effective direction to discover when to stop further investigation while considering the cost and value of the various types of analysis, it helps to avoid over-analyzing empirical data.