 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPION: Layer-Wise Sparse Training of Transformer via Convolutional Flood Filling
Sep 22, 2023

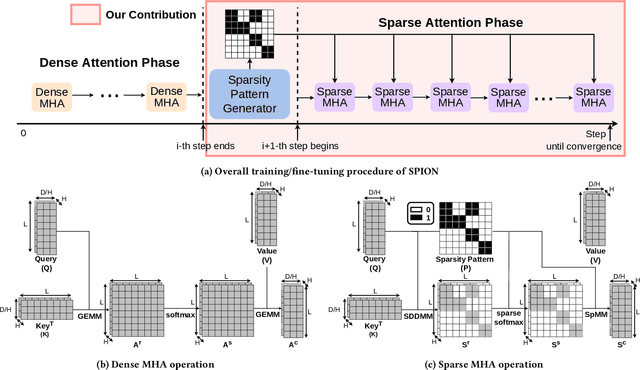

Sparsifying the Transformer has garnered considerable interest, as training the Transformer is very computationally demanding. Prior efforts to sparsify the Transformer have either used a fixed pattern or data-driven approach to reduce the number of operations involving the computation of multi-head attention, which is the main bottleneck of the Transformer. However, existing methods suffer from inevitable problems, such as the potential loss of essential sequence features due to the uniform fixed pattern applied across all layers, and an increase in the model size resulting from the use of additional parameters to learn sparsity patterns in attention operations. In this paper, we propose a novel sparsification scheme for the Transformer that integrates convolution filters and the flood filling method to efficiently capture the layer-wise sparse pattern in attention operations. Our sparsification approach reduces the computational complexity and memory footprint of the Transformer during training. Efficient implementations of the layer-wise sparsified attention algorithm on GPUs are developed, demonstrating a new SPION that achieves up to 3.08X speedup over existing state-of-the-art sparse Transformer models, with better evaluation quality.
Parallel Training of GRU Networks with a Multi-Grid Solver for Long Sequences
Mar 07, 2022

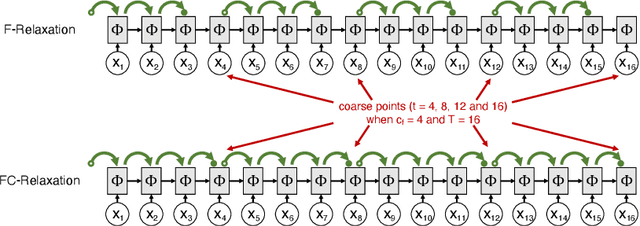

Parallelizing Gated Recurrent Unit (GRU) networks is a challenging task, as the training procedure of GRU is inherently sequential. Prior efforts to parallelize GRU have largely focused on conventional parallelization strategies such as data-parallel and model-parallel training algorithms. However, when the given sequences are very long, existing approaches are still inevitably performance limited in terms of training time. In this paper, we present a novel parallel training scheme (called parallel-in-time) for GRU based on a multigrid reduction in time (MGRIT) solver. MGRIT partitions a sequence into multiple shorter sub-sequences and trains the sub-sequences on different processors in parallel. The key to achieving speedup is a hierarchical correction of the hidden state to accelerate end-to-end communication in both the forward and backward propagation phases of gradient descent. Experimental results on the HMDB51 dataset, where each video is an image sequence, demonstrate that the new parallel training scheme achieves up to 6.5$\times$ speedup over a serial approach. As efficiency of our new parallelization strategy is associated with the sequence length, our parallel GRU algorithm achieves significant performance improvement as the sequence length increases.