 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule by Rule: Learning with Confidence through Vocabulary Expansion
Oct 30, 2024In this paper, we present an innovative iterative approach to rule learning specifically designed for (but not limited to) text-based data. Our method focuses on progressively expanding the vocabulary utilized in each iteration resulting in a significant reduction of memory consumption. Moreover, we introduce a Value of Confidence as an indicator of the reliability of the generated rules. By leveraging the Value of Confidence, our approach ensures that only the most robust and trustworthy rules are retained, thereby improving the overall quality of the rule learning process. We demonstrate the effectiveness of our method through extensive experiments on various textual as well as non-textual datasets including a use case of significant interest to insurance industries, showcasing its potential for real-world applications.
Rule-Based, Neural and LLM Back-Translation: Comparative Insights from a Variant of Ladin
Jul 11, 2024This paper explores the impact of different back-translation approaches on machine translation for Ladin, specifically the Val Badia variant. Given the limited amount of parallel data available for this language (only 18k Ladin-Italian sentence pairs), we investigate the performance of a multilingual neural machine translation model fine-tuned for Ladin-Italian. In addition to the available authentic data, we synthesise further translations by using three different models: a fine-tuned neural model, a rule-based system developed specifically for this language pair, and a large language model. Our experiments show that all approaches achieve comparable translation quality in this low-resource scenario, yet round-trip translations highlight differences in model performance.
A Voting Approach for Explainable Classification with Rule Learning
Nov 13, 2023State-of-the-art results in typical classification tasks are mostly achieved by unexplainable machine learning methods, like deep neural networks, for instance. Contrarily, in this paper, we investigate the application of rule learning methods in such a context. Thus, classifications become based on comprehensible (first-order) rules, explaining the predictions made. In general, however, rule-based classifications are less accurate than state-of-the-art results (often significantly). As main contribution, we introduce a voting approach combining both worlds, aiming to achieve comparable results as (unexplainable) state-of-the-art methods, while still providing explanations in the form of deterministic rules. Considering a variety of benchmark data sets including a use case of significant interest to insurance industries, we prove that our approach not only clearly outperforms ordinary rule learning methods, but also yields results on a par with state-of-the-art outcomes.
Rule Learning by Modularity
Dec 23, 2022



In this paper, we present a modular methodology that combines state-of-the-art methods in (stochastic) machine learning with traditional methods in rule learning to provide efficient and scalable algorithms for the classification of vast data sets, while remaining explainable. Apart from evaluating our approach on the common large scale data sets MNIST, Fashion-MNIST and IMDB, we present novel results on explainable classifications of dental bills. The latter case study stems from an industrial collaboration with Allianz Private Krankenversicherungs-Aktiengesellschaft which is an insurance company offering diverse services in Germany.
The Derivational Complexity Induced by the Dependency Pair Method
Jul 11, 2011

We study the derivational complexity induced by the dependency pair method, enhanced with standard refinements. We obtain upper bounds on the derivational complexity induced by the dependency pair method in terms of the derivational complexity of the base techniques employed. In particular we show that the derivational complexity induced by the dependency pair method based on some direct technique, possibly refined by argument filtering, the usable rules criterion, or dependency graphs, is primitive recursive in the derivational complexity induced by the direct method. This implies that the derivational complexity induced by a standard application of the dependency pair method based on traditional termination orders like KBO, LPO, and MPO is exactly the same as if those orders were applied as the only termination technique.
Dependency Pairs and Polynomial Path Orders
Jun 08, 2011We show how polynomial path orders can be employed efficiently in conjunction with weak innermost dependency pairs to automatically certify polynomial runtime complexity of term rewrite systems and the polytime computability of the functions computed. The established techniques have been implemented and we provide ample experimental data to assess the new method.
Automated Complexity Analysis Based on the Dependency Pair Method
Jun 01, 2011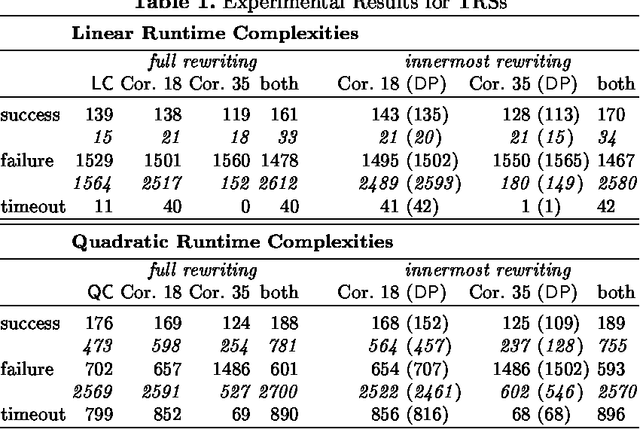
This article is concerned with automated complexity analysis of term rewrite systems. Since these systems underlie much of declarative programming, time complexity of functions defined by rewrite systems is of particular interest. Among other results, we present a variant of the dependency pair method for analysing runtime complexities of term rewrite systems automatically. The established results significantly extent previously known techniques: we give examples of rewrite systems subject to our methods that could previously not been analysed automatically. Furthermore, the techniques have been implemented in the Tyrolean Complexity Tool. We provide ample numerical data for assessing the viability of the method.