 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoNGBa: A Robustly Optimized Natural Gradient Boosting Training Approach with Leaf Number Clipping
Dec 05, 2019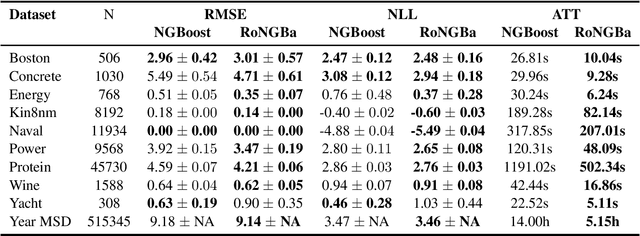
Natural gradient has been recently introduced to the field of boosting to enable the generic probabilistic predication capability. Natural gradient boosting shows promising performance improvements on small datasets due to better training dynamics, but it suffers from slow training speed overhead especially for large datasets. We present a replication study of NGBoost(Duan et al., 2019) training that carefully examines the impacts of key hyper-parameters under the circumstance of best-first decision tree learning. We find that with the regularization of leaf number clipping, the performance of NGBoost can be largely improved via a better choice of hyperparameters. Experiments show that our approach significantly beats the state-of-the-art performance on various kinds of datasets from the UCI Machine Learning Repository while still has up to 4.85x speed up compared with the original approach of NGBoost.