 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatellite Image Classification with Deep Learning
Oct 13, 2020



Satellite imagery is important for many applications including disaster response, law enforcement, and environmental monitoring. These applications require the manual identification of objects and facilities in the imagery. Because the geographic expanses to be covered are great and the analysts available to conduct the searches are few, automation is required. Yet traditional object detection and classification algorithms are too inaccurate and unreliable to solve the problem. Deep learning is a family of machine learning algorithms that have shown promise for the automation of such tasks. It has achieved success in image understanding by means of convolutional neural networks. In this paper we apply them to the problem of object and facility recognition in high-resolution, multi-spectral satellite imagery. We describe a deep learning system for classifying objects and facilities from the IARPA Functional Map of the World (fMoW) dataset into 63 different classes. The system consists of an ensemble of convolutional neural networks and additional neural networks that integrate satellite metadata with image features. It is implemented in Python using the Keras and TensorFlow deep learning libraries and runs on a Linux server with an NVIDIA Titan X graphics card. At the time of writing the system is in 2nd place in the fMoW TopCoder competition. Its total accuracy is 83%, the F1 score is 0.797, and it classifies 15 of the classes with accuracies of 95% or better.
* 7 pages, 18 figures, 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
A Comparison of Deep Learning Object Detection Models for Satellite Imagery
Sep 10, 2020


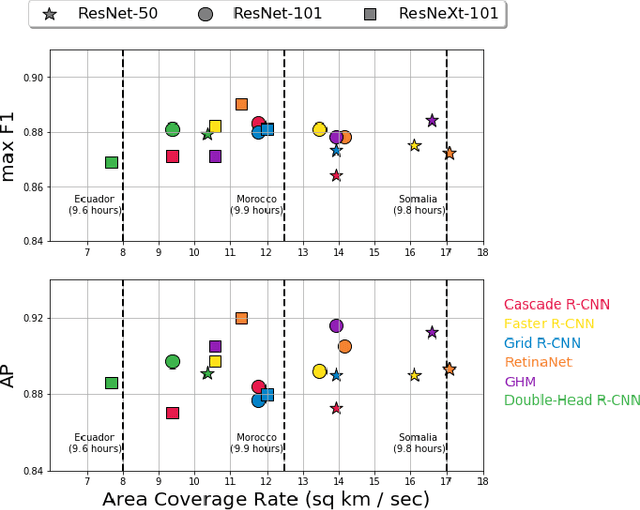
In this work, we compare the detection accuracy and speed of several state-of-the-art models for the task of detecting oil and gas fracking wells and small cars in commercial electro-optical satellite imagery. Several models are studied from the single-stage, two-stage, and multi-stage object detection families of techniques. For the detection of fracking well pads (50m - 250m), we find single-stage detectors provide superior prediction speed while also matching detection performance of their two and multi-stage counterparts. However, for detecting small cars, two-stage and multi-stage models provide substantially higher accuracies at the cost of some speed. We also measure timing results of the sliding window object detection algorithm to provide a baseline for comparison. Some of these models have been incorporated into the Lockheed Martin Globally-Scalable Automated Target Recognition (GATR) framework.
* 10 pages, 9 figures, 3 tables. 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)
Globally-scalable Automated Target Recognition (GATR)
Sep 10, 2020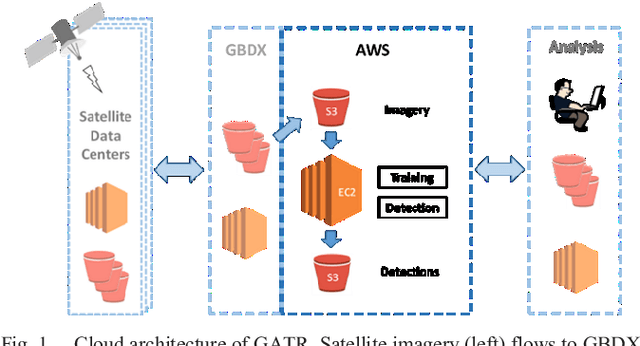
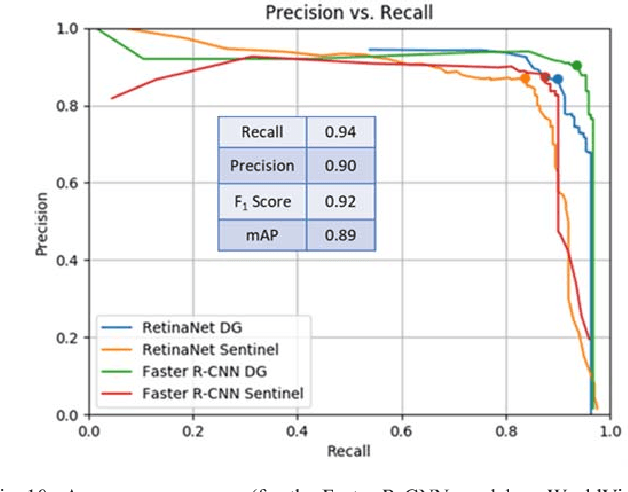

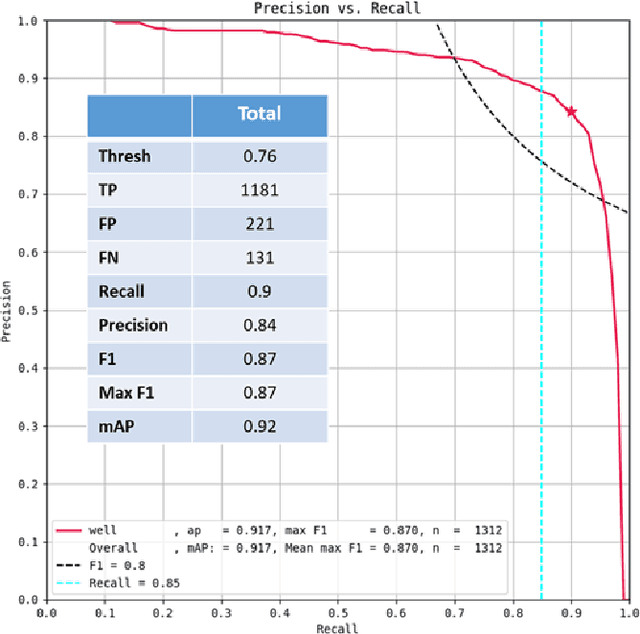
GATR (Globally-scalable Automated Target Recognition) is a Lockheed Martin software system for real-time object detection and classification in satellite imagery on a worldwide basis. GATR uses GPU-accelerated deep learning software to quickly search large geographic regions. On a single GPU it processes imagery at a rate of over 16 square km/sec (or more than 10 Mpixels/sec), and it requires only two hours to search the entire state of Pennsylvania for gas fracking wells. The search time scales linearly with the geographic area, and the processing rate scales linearly with the number of GPUs. GATR has a modular, cloud-based architecture that uses the Maxar GBDX platform and provides an ATR analytic as a service. Applications include broad area search, watch boxes for monitoring ports and airfields, and site characterization. ATR is performed by deep learning models including RetinaNet and Faster R-CNN. Results are presented for the detection of aircraft and fracking wells and show that the recalls exceed 90% even in geographic regions never seen before. GATR is extensible to new targets, such as cars and ships, and it also handles radar and infrared imagery.
* 7 pages, 18 figures, 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)