 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Steps Feature Selection and Neural Network Classification for the TREC-8 Routing
Jul 11, 2000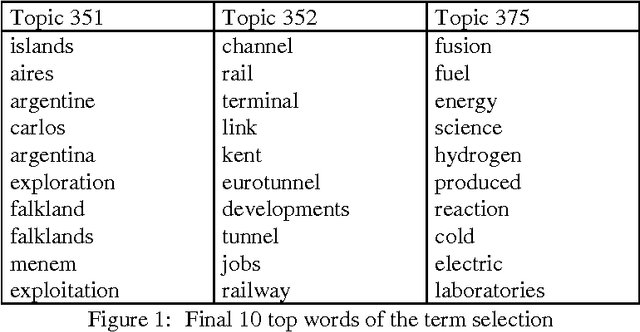
For the TREC-8 routing, one specific filter is built for each topic. Each filter is a classifier trained to recognize the documents that are relevant to the topic. When presented with a document, each classifier estimates the probability for the document to be relevant to the topic for which it has been trained. Since the procedure for building a filter is topic-independent, the system is fully automatic. By making use of a sample of documents that have previously been evaluated as relevant or not relevant to a particular topic, a term selection is performed, and a neural network is trained. Each document is represented by a vector of frequencies of a list of selected terms. This list depends on the topic to be filtered; it is constructed in two steps. The first step defines the characteristic words used in the relevant documents of the corpus; the second one chooses, among the previous list, the most discriminant ones. The length of the vector is optimized automatically for each topic. At the end of the term selection, a vector of typically 25 words is defined for the topic, so that each document which has to be processed is represented by a vector of term frequencies. This vector is subsequently input to a classifier that is trained from the same sample. After training, the classifier estimates for each document of a test set its probability of being relevant; for submission to TREC, the top 1000 documents are ranked in order of decreasing relevance.
Using Learning-based Filters to Detect Rule-based Filtering Obsolescence
Jul 07, 2000


For years, Caisse des Depots et Consignations has produced information filtering applications. To be operational, these applications require high filtering performances which are achieved by using rule-based filters. With this technique, an administrator has to tune a set of rules for each topic. However, filters become obsolescent over time. The decrease of their performances is due to diachronic polysemy of terms that involves a loss of precision and to diachronic polymorphism of concepts that involves a loss of recall. To help the administrator to maintain his filters, we have developed a method which automatically detects filtering obsolescence. It consists in making a learning-based control filter using a set of documents which have already been categorised as relevant or not relevant by the rule-based filter. The idea is to supervise this filter by processing a differential comparison of its outcomes with those of the control one. This method has many advantages. It is simple to implement since the training set used by the learning is supplied by the rule-based filter. Thus, both the making and the use of the control filter are fully automatic. With automatic detection of obsolescence, learning-based filtering finds a rich application which offers interesting prospects.
Producing NLP-based On-line Contentware
Sep 16, 1998
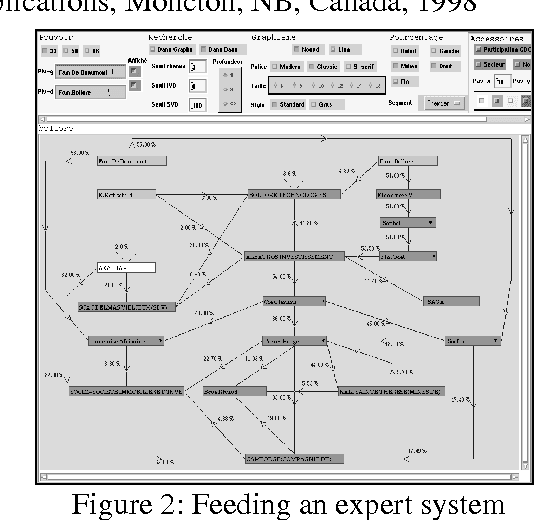

For its internal needs as well as for commercial purposes, CDC Group has produced several NLP-based on-line contentware applications for years. The development process of such applications is subject to numerous constraints such as quality of service, integration of new advances in NLP, direct reactions from users, continuous versioning, short delivery deadlines and cost control. Following this industrial and commercial experience, malleability of the applications, their openness towards foreign components, efficiency of applications and their ease of exploitation have appeared to be key points. In this paper, we describe TalLab, a powerful architecture for on-line contentware which fulfils these requirements.
* 7 pages, 5 figures
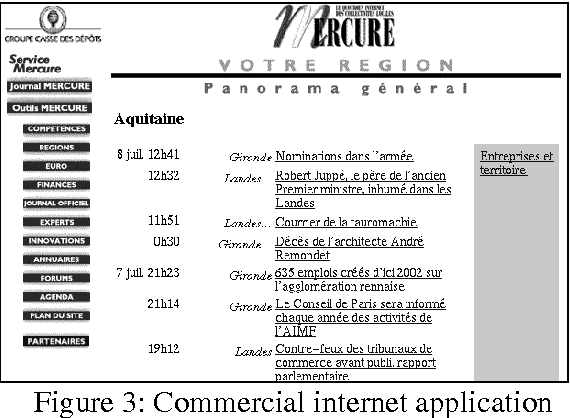
Automatic processing proper names in texts
Apr 05, 1995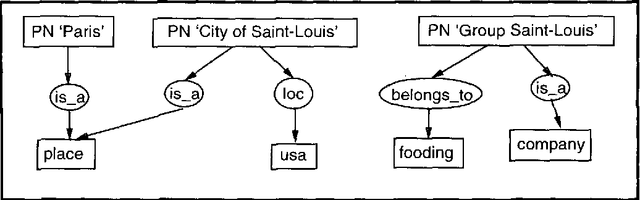

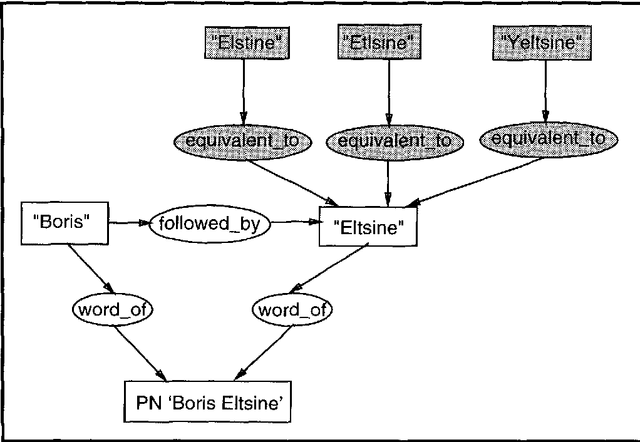
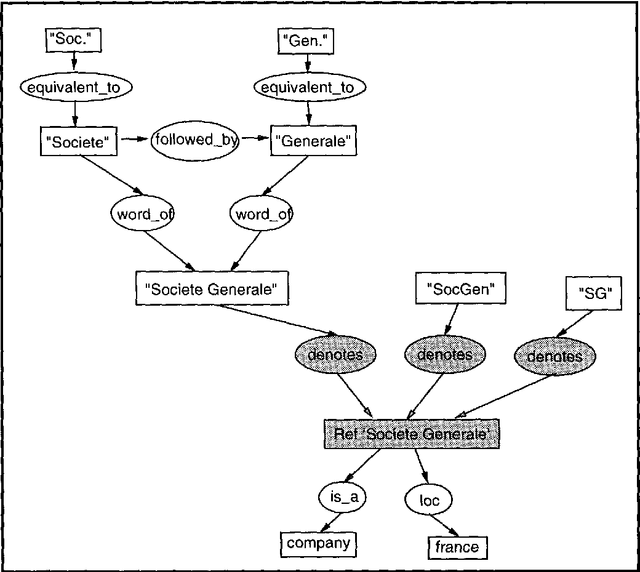
This paper shows first the problems raised by proper names in natural language processing. Second, it introduces the knowledge representation structure we use based on conceptual graphs. Then it explains the techniques which are used to process known and unknown proper names. At last, it gives the performance of the system and the further works we intend to deal with.