 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypCBC: Domain-Invariant Hyperbolic Cross-Branch Consistency for Generalizable Medical Image Analysis
Feb 03, 2026Robust generalization beyond training distributions remains a critical challenge for deep neural networks. This is especially pronounced in medical image analysis, where data is often scarce and covariate shifts arise from different hardware devices, imaging protocols, and heterogeneous patient populations. These factors collectively hinder reliable performance and slow down clinical adoption. Despite recent progress, existing learning paradigms primarily rely on the Euclidean manifold, whose flat geometry fails to capture the complex, hierarchical structures present in clinical data. In this work, we exploit the advantages of hyperbolic manifolds to model complex data characteristics. We present the first comprehensive validation of hyperbolic representation learning for medical image analysis and demonstrate statistically significant gains across eleven in-distribution datasets and three ViT models. We further propose an unsupervised, domain-invariant hyperbolic cross-branch consistency constraint. Extensive experiments confirm that our proposed method promotes domain-invariant features and outperforms state-of-the-art Euclidean methods by an average of $+2.1\%$ AUC on three domain generalization benchmarks: Fitzpatrick17k, Camelyon17-WILDS, and a cross-dataset setup for retinal imaging. These datasets span different imaging modalities, data sizes, and label granularities, confirming generalization capabilities across substantially different conditions. The code is available at https://github.com/francescodisalvo05/hyperbolic-cross-branch-consistency .
Stylizing ViT: Anatomy-Preserving Instance Style Transfer for Domain Generalization
Jan 24, 2026Deep learning models in medical image analysis often struggle with generalizability across domains and demographic groups due to data heterogeneity and scarcity. Traditional augmentation improves robustness, but fails under substantial domain shifts. Recent advances in stylistic augmentation enhance domain generalization by varying image styles but fall short in terms of style diversity or by introducing artifacts into the generated images. To address these limitations, we propose Stylizing ViT, a novel Vision Transformer encoder that utilizes weight-shared attention blocks for both self- and cross-attention. This design allows the same attention block to maintain anatomical consistency through self-attention while performing style transfer via cross-attention. We assess the effectiveness of our method for domain generalization by employing it for data augmentation on three distinct image classification tasks in the context of histopathology and dermatology. Results demonstrate an improved robustness (up to +13% accuracy) over the state of the art while generating perceptually convincing images without artifacts. Additionally, we show that Stylizing ViT is effective beyond training, achieving a 17% performance improvement during inference when used for test-time augmentation. The source code is available at https://github.com/sdoerrich97/stylizing-vit .
Embedding-Based Federated Data Sharing via Differentially Private Conditional VAEs
Jul 03, 2025Deep Learning (DL) has revolutionized medical imaging, yet its adoption is constrained by data scarcity and privacy regulations, limiting access to diverse datasets. Federated Learning (FL) enables decentralized training but suffers from high communication costs and is often restricted to a single downstream task, reducing flexibility. We propose a data-sharing method via Differentially Private (DP) generative models. By adopting foundation models, we extract compact, informative embeddings, reducing redundancy and lowering computational overhead. Clients collaboratively train a Differentially Private Conditional Variational Autoencoder (DP-CVAE) to model a global, privacy-aware data distribution, supporting diverse downstream tasks. Our approach, validated across multiple feature extractors, enhances privacy, scalability, and efficiency, outperforming traditional FL classifiers while ensuring differential privacy. Additionally, DP-CVAE produces higher-fidelity embeddings than DP-CGAN while requiring $5{\times}$ fewer parameters.
An Embedding is Worth a Thousand Noisy Labels
Aug 26, 2024The performance of deep neural networks scales with dataset size and label quality, rendering the efficient mitigation of low-quality data annotations crucial for building robust and cost-effective systems. Existing strategies to address label noise exhibit severe limitations due to computational complexity and application dependency. In this work, we propose WANN, a Weighted Adaptive Nearest Neighbor approach that builds on self-supervised feature representations obtained from foundation models. To guide the weighted voting scheme, we introduce a reliability score, which measures the likelihood of a data label being correct. WANN outperforms reference methods, including a linear layer trained with robust loss functions, on diverse datasets of varying size and under various noise types and severities. WANN also exhibits superior generalization on imbalanced data compared to both Adaptive-NNs (ANN) and fixed k-NNs. Furthermore, the proposed weighting scheme enhances supervised dimensionality reduction under noisy labels. This yields a significant boost in classification performance with 10x and 100x smaller image embeddings, minimizing latency and storage requirements. Our approach, emphasizing efficiency and explainability, emerges as a simple, robust solution to overcome the inherent limitations of deep neural network training. The code is available at https://github.com/francescodisalvo05/wann-noisy-labels .
Privacy-preserving datasets by capturing feature distributions with Conditional VAEs
Aug 01, 2024



Large and well-annotated datasets are essential for advancing deep learning applications, however often costly or impossible to obtain by a single entity. In many areas, including the medical domain, approaches relying on data sharing have become critical to address those challenges. While effective in increasing dataset size and diversity, data sharing raises significant privacy concerns. Commonly employed anonymization methods based on the k-anonymity paradigm often fail to preserve data diversity, affecting model robustness. This work introduces a novel approach using Conditional Variational Autoencoders (CVAEs) trained on feature vectors extracted from large pre-trained vision foundation models. Foundation models effectively detect and represent complex patterns across diverse domains, allowing the CVAE to faithfully capture the embedding space of a given data distribution to generate (sample) a diverse, privacy-respecting, and potentially unbounded set of synthetic feature vectors. Our method notably outperforms traditional approaches in both medical and natural image domains, exhibiting greater dataset diversity and higher robustness against perturbations while preserving sample privacy. These results underscore the potential of generative models to significantly impact deep learning applications in data-scarce and privacy-sensitive environments. The source code is available at https://github.com/francescodisalvo05/cvae-anonymization .
Self-supervised Vision Transformer are Scalable Generative Models for Domain Generalization
Jul 03, 2024Despite notable advancements, the integration of deep learning (DL) techniques into impactful clinical applications, particularly in the realm of digital histopathology, has been hindered by challenges associated with achieving robust generalization across diverse imaging domains and characteristics. Traditional mitigation strategies in this field such as data augmentation and stain color normalization have proven insufficient in addressing this limitation, necessitating the exploration of alternative methodologies. To this end, we propose a novel generative method for domain generalization in histopathology images. Our method employs a generative, self-supervised Vision Transformer to dynamically extract characteristics of image patches and seamlessly infuse them into the original images, thereby creating novel, synthetic images with diverse attributes. By enriching the dataset with such synthesized images, we aim to enhance its holistic nature, facilitating improved generalization of DL models to unseen domains. Extensive experiments conducted on two distinct histopathology datasets demonstrate the effectiveness of our proposed approach, outperforming the state of the art substantially, on the Camelyon17-wilds challenge dataset (+2%) and on a second epithelium-stroma dataset (+26%). Furthermore, we emphasize our method's ability to readily scale with increasingly available unlabeled data samples and more complex, higher parametric architectures. Source code is available at https://github.com/sdoerrich97/vits-are-generative-models .
MedMNIST-C: Comprehensive benchmark and improved classifier robustness by simulating realistic image corruptions
Jun 26, 2024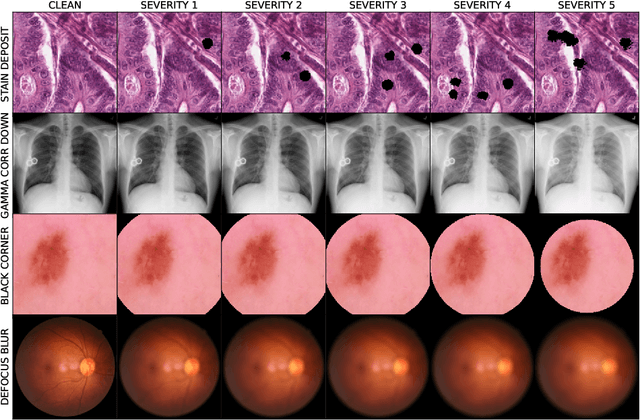


The integration of neural-network-based systems into clinical practice is limited by challenges related to domain generalization and robustness. The computer vision community established benchmarks such as ImageNet-C as a fundamental prerequisite to measure progress towards those challenges. Similar datasets are largely absent in the medical imaging community which lacks a comprehensive benchmark that spans across imaging modalities and applications. To address this gap, we create and open-source MedMNIST-C, a benchmark dataset based on the MedMNIST+ collection covering 12 datasets and 9 imaging modalities. We simulate task and modality-specific image corruptions of varying severity to comprehensively evaluate the robustness of established algorithms against real-world artifacts and distribution shifts. We further provide quantitative evidence that our simple-to-use artificial corruptions allow for highly performant, lightweight data augmentation to enhance model robustness. Unlike traditional, generic augmentation strategies, our approach leverages domain knowledge, exhibiting significantly higher robustness when compared to widely adopted methods. By introducing MedMNIST-C and open-sourcing the corresponding library allowing for targeted data augmentations, we contribute to the development of increasingly robust methods tailored to the challenges of medical imaging. The code is available at https://github.com/francescodisalvo05/medmnistc-api}{github.com/francescodisalvo05/medmnistc-api .
Rethinking Model Prototyping through the MedMNIST+ Dataset Collection
Apr 24, 2024The integration of deep learning based systems in clinical practice is often impeded by challenges rooted in limited and heterogeneous medical datasets. In addition, prioritization of marginal performance improvements on a few, narrowly scoped benchmarks over clinical applicability has slowed down meaningful algorithmic progress. This trend often results in excessive fine-tuning of existing methods to achieve state-of-the-art performance on selected datasets rather than fostering clinically relevant innovations. In response, this work presents a comprehensive benchmark for the MedMNIST+ database to diversify the evaluation landscape and conduct a thorough analysis of common convolutional neural networks (CNNs) and Transformer-based architectures, for medical image classification. Our evaluation encompasses various medical datasets, training methodologies, and input resolutions, aiming to reassess the strengths and limitations of widely used model variants. Our findings suggest that computationally efficient training schemes and modern foundation models hold promise in bridging the gap between expensive end-to-end training and more resource-refined approaches. Additionally, contrary to prevailing assumptions, we observe that higher resolutions may not consistently improve performance beyond a certain threshold, advocating for the use of lower resolutions, particularly in prototyping stages, to expedite processing. Notably, our analysis reaffirms the competitiveness of convolutional models compared to ViT-based architectures emphasizing the importance of comprehending the intrinsic capabilities of different model architectures. Moreover, we hope that our standardized evaluation framework will help enhance transparency, reproducibility, and comparability on the MedMNIST+ dataset collection as well as future research within the field. Code will be released soon.
Integrating kNN with Foundation Models for Adaptable and Privacy-Aware Image Classification
Feb 19, 2024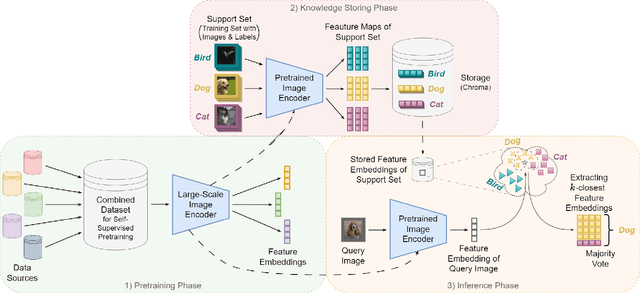



Traditional deep learning models implicity encode knowledge limiting their transparency and ability to adapt to data changes. Yet, this adaptability is vital for addressing user data privacy concerns. We address this limitation by storing embeddings of the underlying training data independently of the model weights, enabling dynamic data modifications without retraining. Specifically, our approach integrates the $k$-Nearest Neighbor ($k$-NN) classifier with a vision-based foundation model, pre-trained self-supervised on natural images, enhancing interpretability and adaptability. We share open-source implementations of a previously unpublished baseline method as well as our performance-improving contributions. Quantitative experiments confirm improved classification across established benchmark datasets and the method's applicability to distinct medical image classification tasks. Additionally, we assess the method's robustness in continual learning and data removal scenarios. The approach exhibits great promise for bridging the gap between foundation models' performance and challenges tied to data privacy. The source code is available at https://github.com/TobArc/privacy-aware-image-classification-with-kNN.
unORANIC: Unsupervised Orthogonalization of Anatomy and Image-Characteristic Features
Aug 29, 2023We introduce unORANIC, an unsupervised approach that uses an adapted loss function to drive the orthogonalization of anatomy and image-characteristic features. The method is versatile for diverse modalities and tasks, as it does not require domain knowledge, paired data samples, or labels. During test time unORANIC is applied to potentially corrupted images, orthogonalizing their anatomy and characteristic components, to subsequently reconstruct corruption-free images, showing their domain-invariant anatomy only. This feature orthogonalization further improves generalization and robustness against corruptions. We confirm this qualitatively and quantitatively on 5 distinct datasets by assessing unORANIC's classification accuracy, corruption detection and revision capabilities. Our approach shows promise for enhancing the generalizability and robustness of practical applications in medical image analysis. The source code is available at https://github.com/sdoerrich97/unORANIC.