 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT Transformer model for Detecting Arabic GPT2 Auto-Generated Tweets
Jan 22, 2021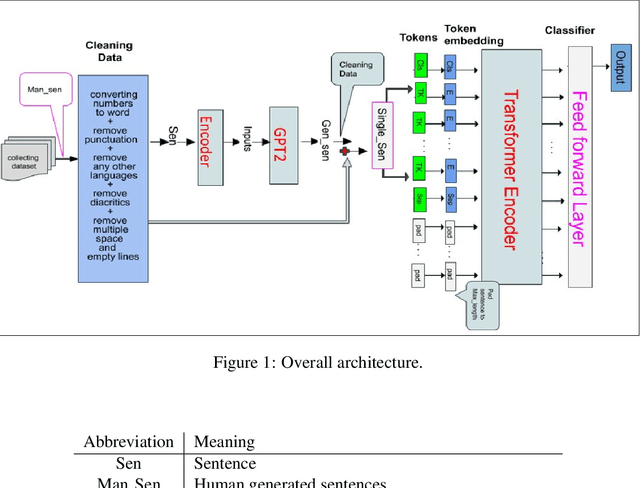

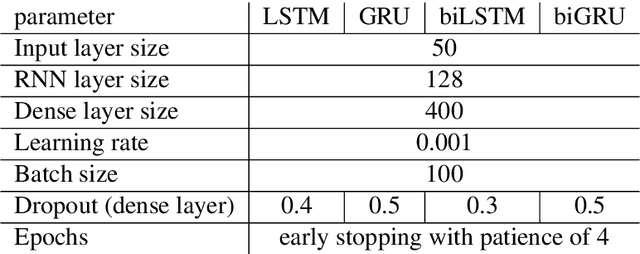
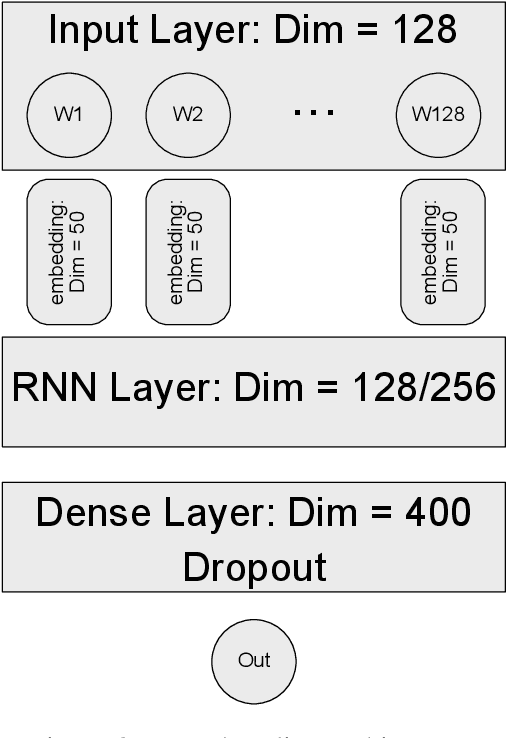
During the last two decades, we have progressively turned to the Internet and social media to find news, entertain conversations and share opinion. Recently, OpenAI has developed a ma-chine learning system called GPT-2 for Generative Pre-trained Transformer-2, which can pro-duce deepfake texts. It can generate blocks of text based on brief writing prompts that look like they were written by humans, facilitating the spread false or auto-generated text. In line with this progress, and in order to counteract potential dangers, several methods have been pro-posed for detecting text written by these language models. In this paper, we propose a transfer learning based model that will be able to detect if an Arabic sentence is written by humans or automatically generated by bots. Our dataset is based on tweets from a previous work, which we have crawled and extended using the Twitter API. We used GPT2-Small-Arabic to generate fake Arabic Sentences. For evaluation, we compared different recurrent neural network (RNN) word embeddings based baseline models, namely: LSTM, BI-LSTM, GRU and BI-GRU, with a transformer-based model. Our new transfer-learning model has obtained an accuracy up to 98%. To the best of our knowledge, this work is the first study where ARABERT and GPT2 were combined to detect and classify the Arabic auto-generated texts.
Arabic Opinion Mining Using a Hybrid Recommender System Approach
Sep 16, 2020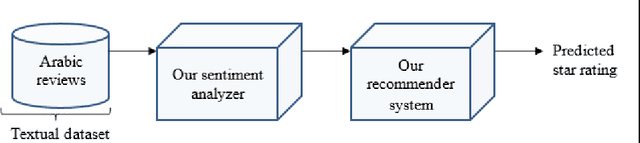
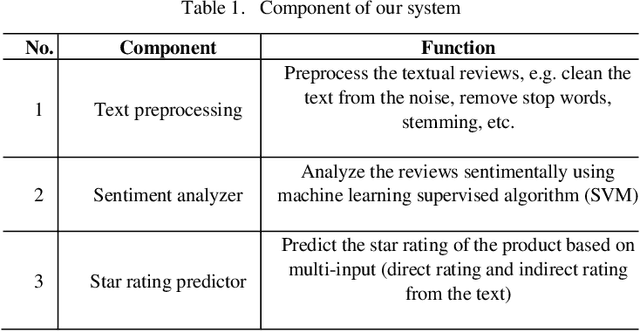


Recommender systems nowadays are playing an important role in the delivery of services and information to users. Sentiment analysis (also known as opinion mining) is the process of determining the attitude of textual opinions, whether they are positive, negative or neutral. Data sparsity is representing a big issue for recommender systems because of the insufficiency of user rating or absence of data about users or items. This research proposed a hybrid approach combining sentiment analysis and recommender systems to tackle the problem of data sparsity problems by predicting the rating of products from users reviews using text mining and NLP techniques. This research focuses especially on Arabic reviews, where the model is evaluated using Opinion Corpus for Arabic (OCA) dataset. Our system was efficient, and it showed a good accuracy of nearly 85 percent in predicting rating from reviews
Quran Intelligent Ontology Construction Approach Using Association Rules Mining
Aug 10, 2020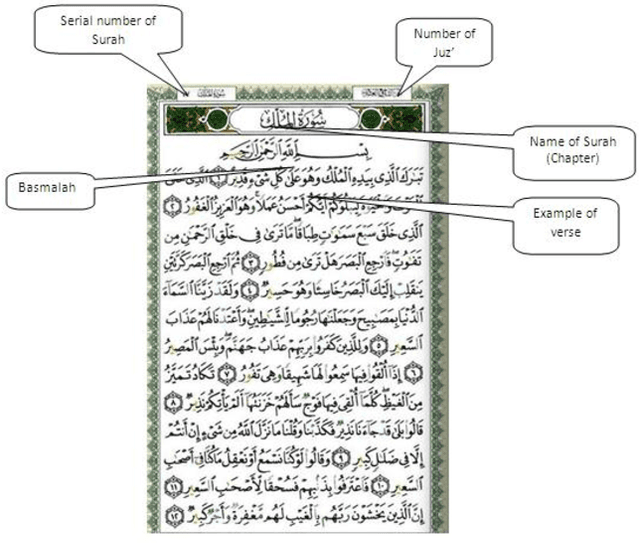

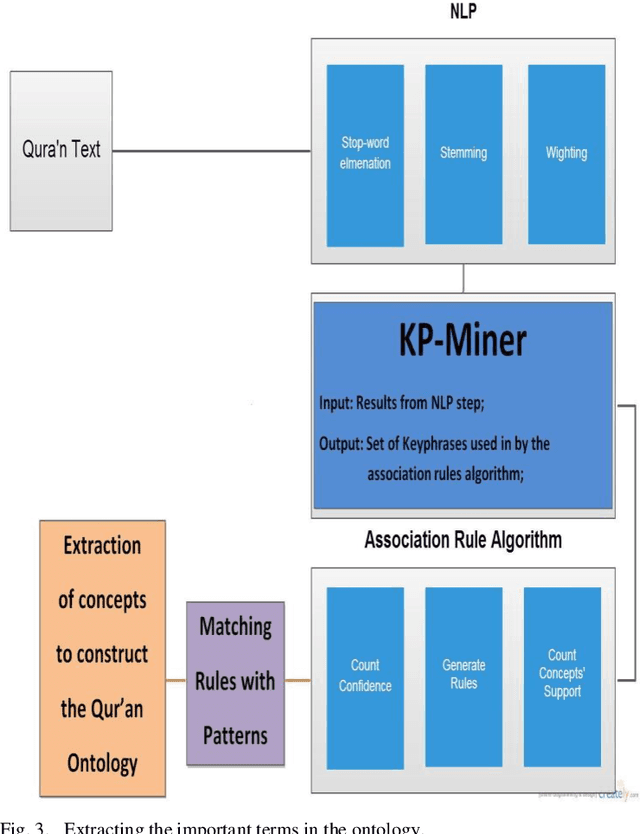

Ontology can be seen as a formal representation of knowledge. They have been investigated in many artificial intelligence studies including semantic web, software engineering, and information retrieval. The aim of ontology is to develop knowledge representations that can be shared and reused. This research project is concerned with the use of association rules to extract the Quran ontology. The manual acquisition of ontologies from Quran verses can be very costly; therefore, we need an intelligent system for Quran ontology construction using patternbased schemes and associations rules to discover Quran concepts and semantics relations from Quran verses. Our system is based on the combination of statistics and linguistics methods to extract concepts and conceptual relations from Quran. In particular, a linguistic pattern-based approach is exploited to extract specific concepts from the Quran, while the conceptual relations are found based on association rules technique. The Quran ontology will offer a new and powerful representation of Quran knowledge, and the association rules will help to represent the relations between all classes of connected concepts in the Quran ontology.