 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Shape-Constrained Regression Algorithms for Data Validation
Sep 20, 2022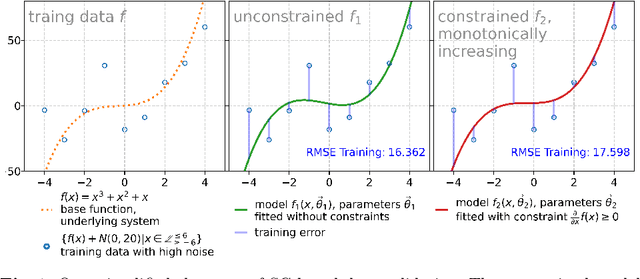
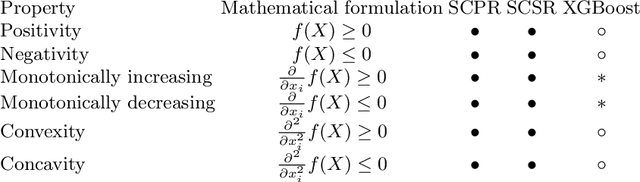
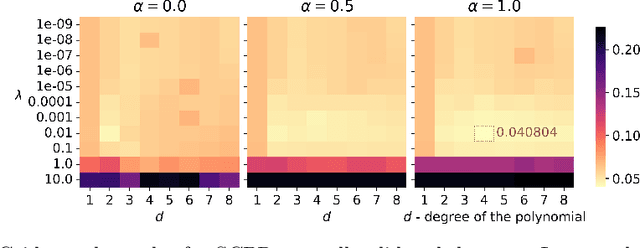
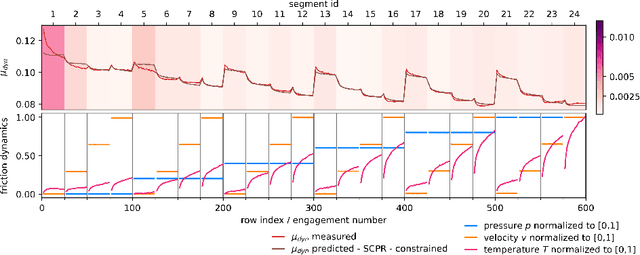
Industrial and scientific applications handle large volumes of data that render manual validation by humans infeasible. Therefore, we require automated data validation approaches that are able to consider the prior knowledge of domain experts to produce dependable, trustworthy assessments of data quality. Prior knowledge is often available as rules that describe interactions of inputs with regard to the target e.g. the target must be monotonically decreasing and convex over increasing input values. Domain experts are able to validate multiple such interactions at a glance. However, existing rule-based data validation approaches are unable to consider these constraints. In this work, we compare different shape-constrained regression algorithms for the purpose of data validation based on their classification accuracy and runtime performance.
Concept for a Technical Infrastructure for Management of Predictive Models in Industrial Applications
Jul 29, 2021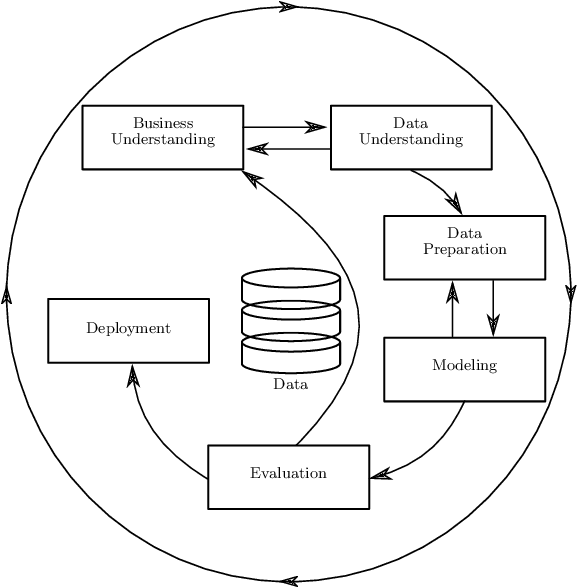
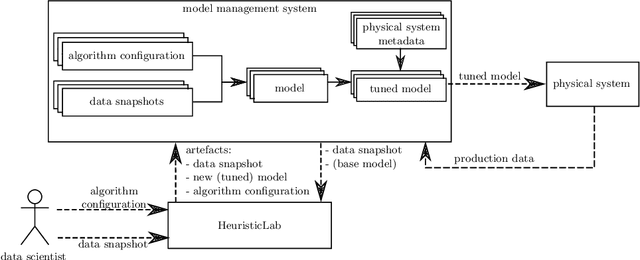
With the increasing number of created and deployed prediction models and the complexity of machine learning workflows we require so called model management systems to support data scientists in their tasks. In this work we describe our technological concept for such a model management system. This concept includes versioned storage of data, support for different machine learning algorithms, fine tuning of models, subsequent deployment of models and monitoring of model performance after deployment. We describe this concept with a close focus on model lifecycle requirements stemming from our industry application cases, but generalize key features that are relevant for all applications of machine learning.
* International Conference on Computer Aided Systems Theory, Eurocast 2019, pp 263-270