 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Customer Needs Analysis: A Comparative Study of Large Language Models in the Travel Industry
Apr 27, 2024In the rapidly evolving landscape of Natural Language Processing (NLP), Large Language Models (LLMs) have emerged as powerful tools for many tasks, such as extracting valuable insights from vast amounts of textual data. In this study, we conduct a comparative analysis of LLMs for the extraction of travel customer needs from TripAdvisor posts. Leveraging a diverse range of models, including both open-source and proprietary ones such as GPT-4 and Gemini, we aim to elucidate their strengths and weaknesses in this specialized domain. Through an evaluation process involving metrics such as BERTScore, ROUGE, and BLEU, we assess the performance of each model in accurately identifying and summarizing customer needs. Our findings highlight the efficacy of opensource LLMs, particularly Mistral 7B, in achieving comparable performance to larger closed models while offering affordability and customization benefits. Additionally, we underscore the importance of considering factors such as model size, resource requirements, and performance metrics when selecting the most suitable LLM for customer needs analysis tasks. Overall, this study contributes valuable insights for businesses seeking to leverage advanced NLP techniques to enhance customer experience and drive operational efficiency in the travel industry.
Defining definition: a Text mining Approach to Define Innovative Technological Fields
Jun 08, 2021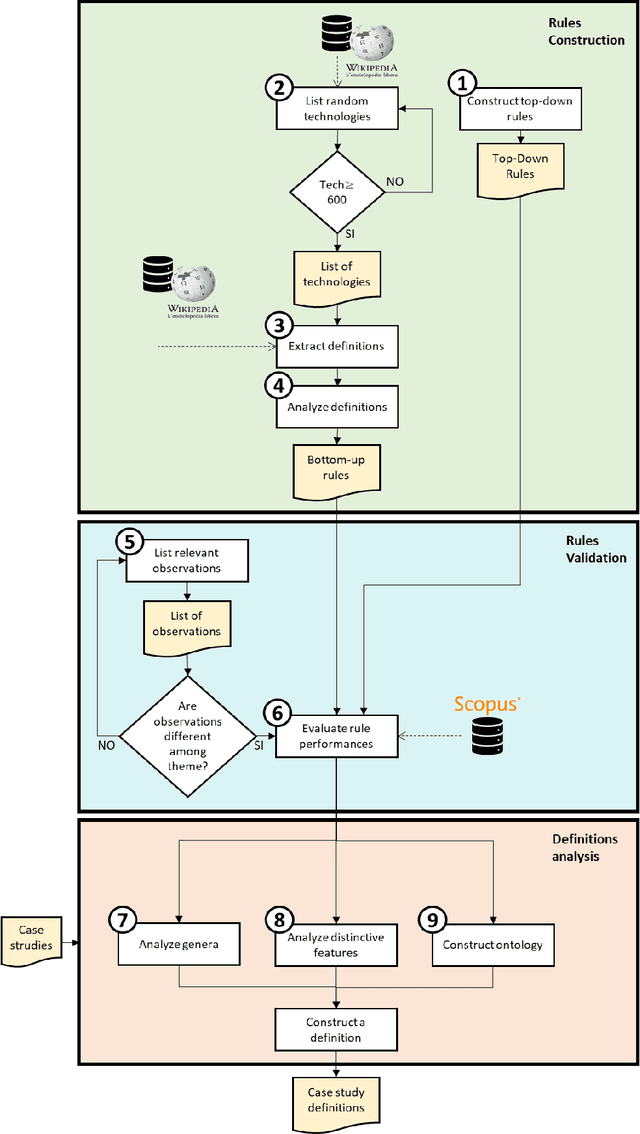
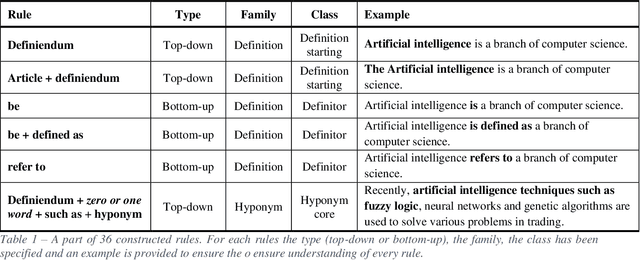
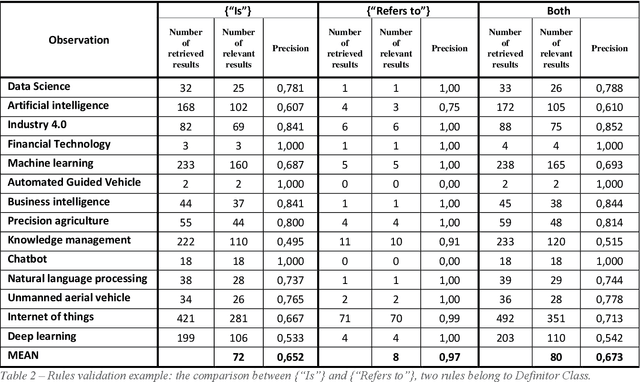
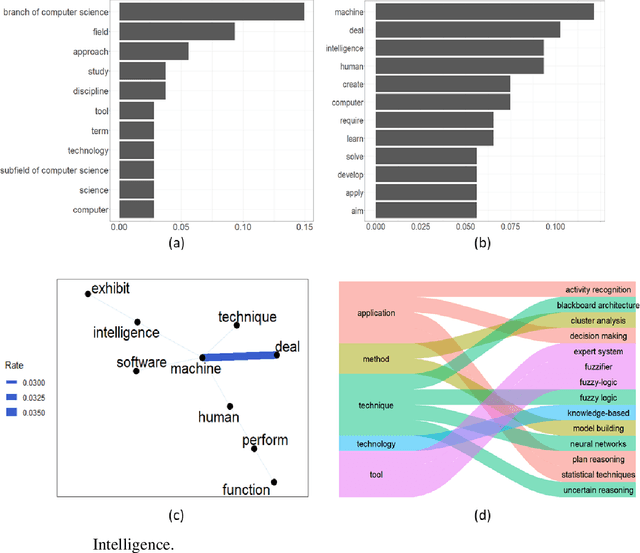
One of the first task of an innovative project is delineating the scope of the project itself or of the product/service to be developed. A wrong scope definition can determine (in the worst case) project failure. A good scope definition become even more relevant in technological intensive innovation projects, nowadays characterized by a highly dynamic multidisciplinary, turbulent and uncertain environment. In these cases, the boundaries of the project are not easily detectable and it is difficult to decide what it is in-scope and out-of-scope. The present work proposes a tool for the scope delineation process, that automatically define an innovative technological field or a new technology. The tool is based on Text Mining algorithm that exploits Elsevier's Scopus abstracts in order to the extract relevant data to define a technological scope. The automatic definition tool is then applied on four case studies: Artificial Intelligence and Data Science. The results show how the tool can provide many crucial information in the definition process of a technological field. In particular for the target technological field (or technology), it provides the definition and other elements related to the target.
Rapid detection of fast innovation under the pressure of COVID-19
Jan 30, 2021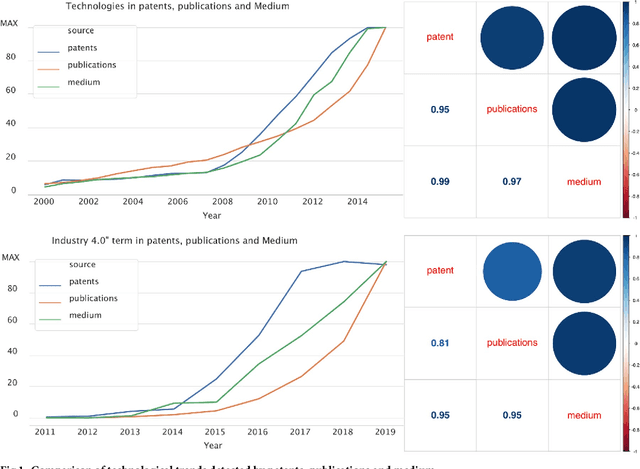

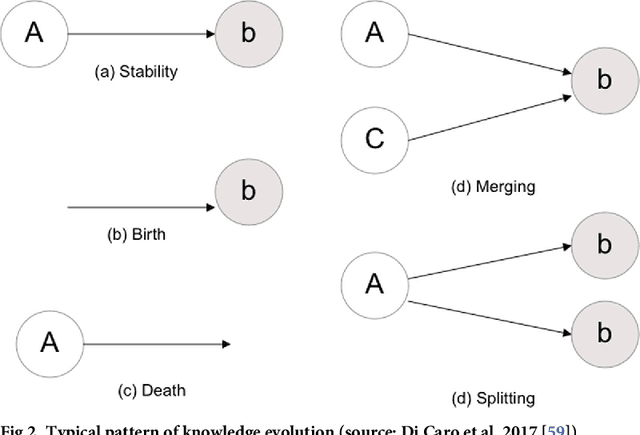
Covid-19 has rapidly redefined the agenda of technological research and development both for academics and practitioners. If the medical scientific publication system has promptly reacted to this new situation, other domains, particularly in new technologies, struggle to map what is happening in their contexts. The pandemic has created the need for a rapid detection of technological convergence phenomena, but at the same time it has made clear that this task is impossible on the basis of traditional patent and publication indicators. This paper presents a novel methodology to perform a rapid detection of the fast technological convergence phenomenon that is occurring under the pressure of the Covid-19 pandemic. The fast detection has been performed thanks to the use of a novel source: the online blogging platform Medium. We demonstrate that the hybrid structure of this social journalism platform allows a rapid detection of innovation phenomena, unlike other traditional sources. The technological convergence phenomenon has been modelled through a network-based approach, analysing the differences of networks computed during two time periods (pre and post COVID-19). The results led us to discuss the repurposing of technologies regarding "Remote Control", "Remote Working", "Health" and "Remote Learning".
* Published in PlOs One in 12/31/2020
SkillNER: Mining and Mapping Soft Skills from any Text
Jan 22, 2021
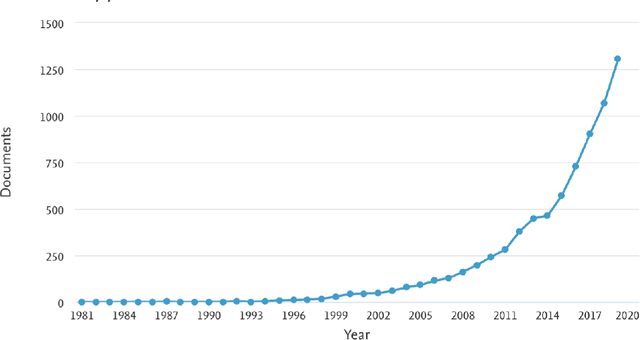
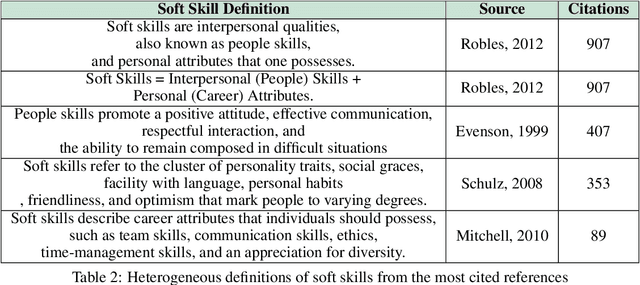
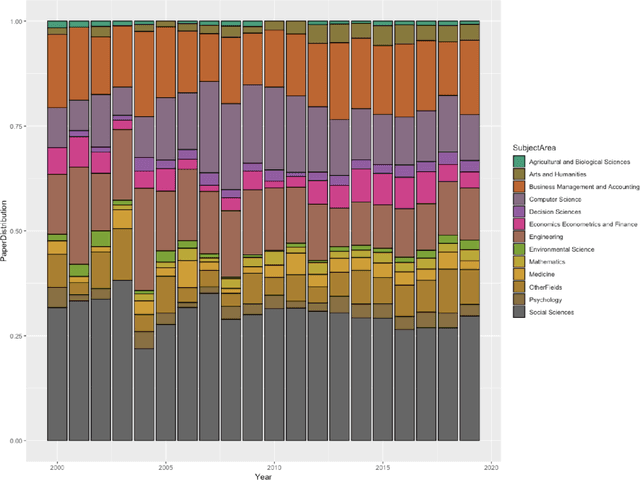
In today's digital world there is an increasing focus on soft skills. The reasons are many, however the main ones can be traced down to the increased complexity of labor market dynamics and the shift towards digitalisation. Digitalisation has also increased the focus on soft skills, since such competencies are hardly acquired by Artificial Intelligence Systems. Despite this growing interest, researchers struggle in accurately defining the soft skill concept and in creating a complete and shared list of soft skills. Therefore, the aim of the present paper is the development of an automated tool capable of extracting soft skills from unstructured texts. Starting from an initial seed list of soft skills, we automatically collect a set of possible textual expressions referring to soft skills, thus creating a Soft Skills list. This has been done by applying Named Entity Recognition (NER) on a corpus of scientific papers developing a novel approach and a software application able to perform the automatic extraction of soft skills from text: the SkillNER. We measured the performance of the tools considering different training models and validated our approach comparing our list of soft skills with the skills labelled as transversal in ESCO (European Skills/Competence Qualification and Occupation). Finally we give a first example of how the SkillNER can be used, identifying the relationships among ESCO job profiles based on soft skills shared, and the relationships among soft skills based on job profiles in common. The final map of soft skills-job profiles may help accademia in achieving and sharing a clearer definition of what soft skills are and fuel future quantitative research on the topic.