 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Text using Language Modelling based on Phonetics and String Similarity
Jun 25, 2020
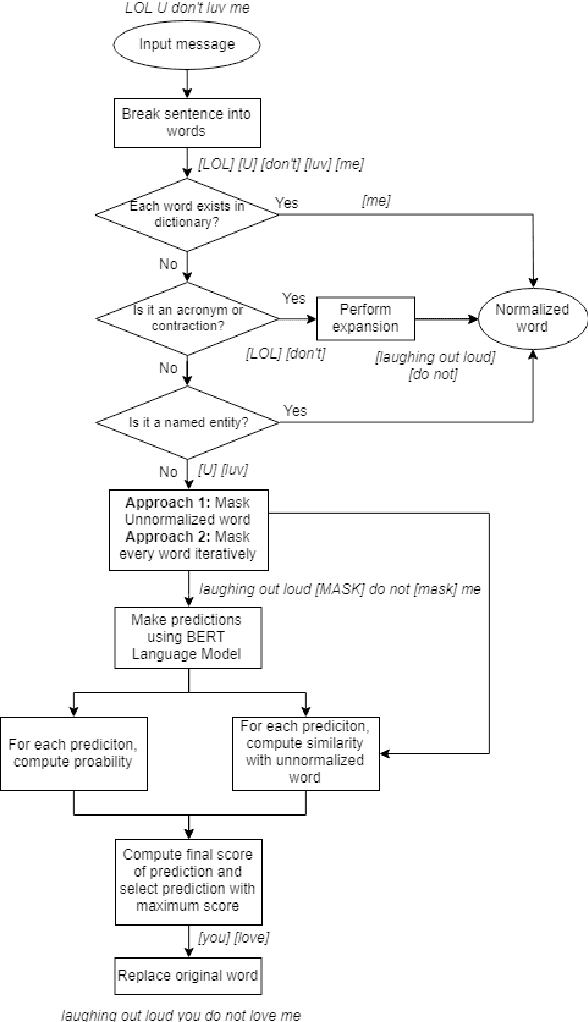

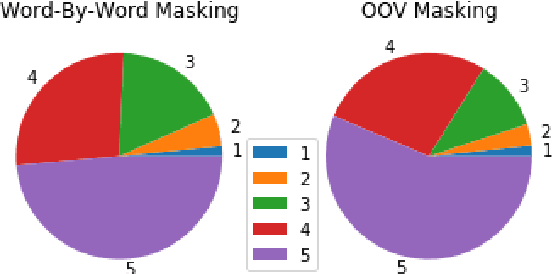
Social media networks and chatting platforms often use an informal version of natural text. Adversarial spelling attacks also tend to alter the input text by modifying the characters in the text. Normalizing these texts is an essential step for various applications like language translation and text to speech synthesis where the models are trained over clean regular English language. We propose a new robust model to perform text normalization. Our system uses the BERT language model to predict the masked words that correspond to the unnormalized words. We propose two unique masking strategies that try to replace the unnormalized words in the text with their root form using a unique score based on phonetic and string similarity metrics.We use human-centric evaluations where volunteers were asked to rank the normalized text. Our strategies yield an accuracy of 86.7% and 83.2% which indicates the effectiveness of our system in dealing with text normalization.