 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAge of Information in Multi-Relay Networks with Maximum Age Scheduling
Mar 20, 2025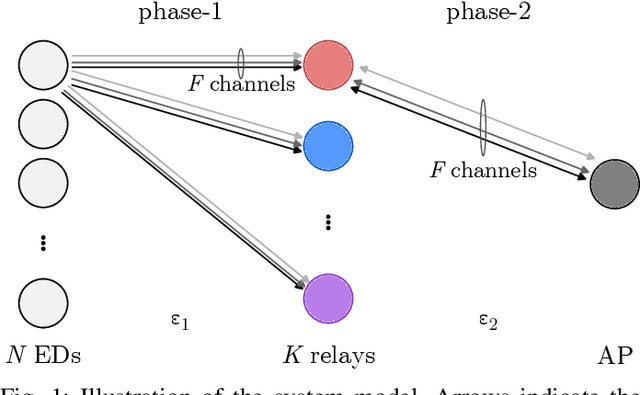
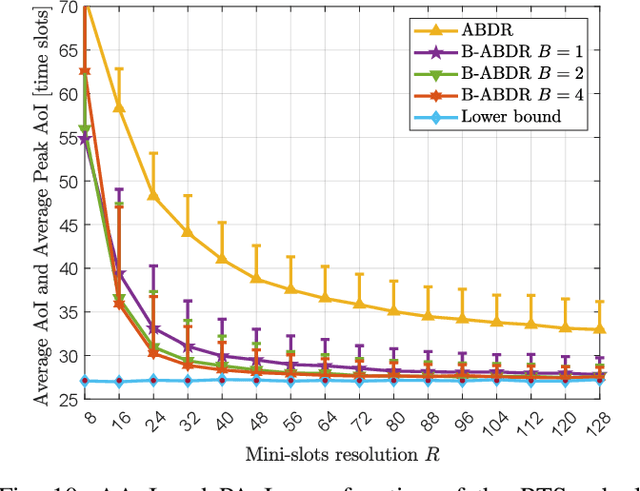
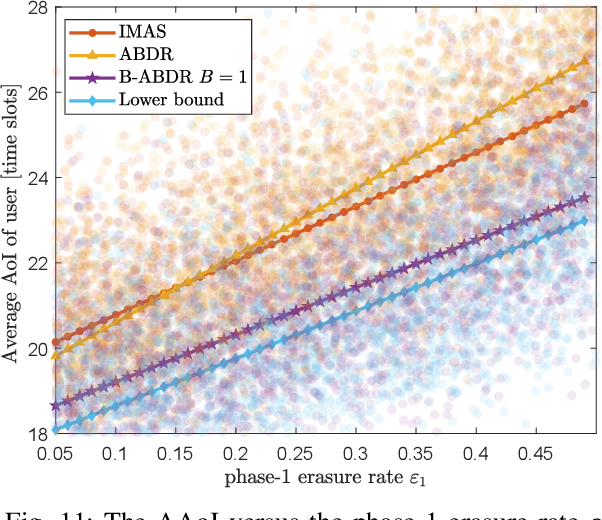
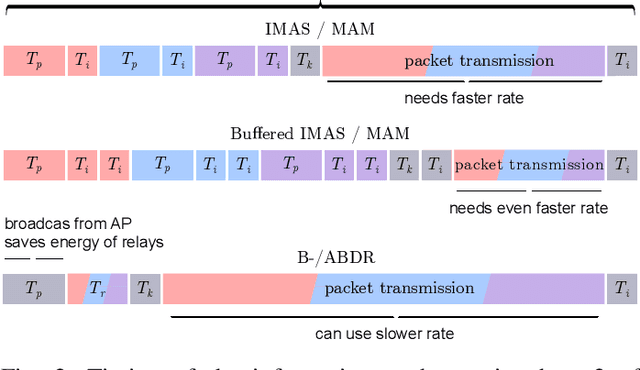
We propose and evaluate age of information (AoI)-aware multiple access mechanisms for the Internet of Things (IoT) in multi-relay two-hop networks. The network considered comprises end devices (EDs) communicating with a set of relays in ALOHA fashion, with new information packets to be potentially transmitted every time slot. The relays, in turn, forward the collected packets to an access point (AP), the final destination of the information generated by the EDs. More specifically, in this work we investigate the performance of four age-aware algorithms that prioritize older packets to be transmitted, namely max-age matching (MAM), iterative max-age scheduling (IMAS), age-based delayed request (ABDR), and buffered ABDR (B-ABDR). The former two algorithms are adapted into the multi-relay setup from previous research, and achieve satisfactory average AoI and average peak AoI performance, at the expense of a significant amount of information exchange between the relays and the AP. The latter two algorithms are newly proposed to let relays decide which one(s) will transmit in a given time slot, requiring less signaling than the former algorithms. We provide an analytical formulation for the AoI lower bound performance, compare the performance of all algorithms in this set-up, and show that they approach the lower bound. The latter holds especially true for B-ABDR, which approaches the lower bound the most closely, tilting the scale in its favor, as it also requires far less signaling than MAM and IMAS.
Reinforcenment Learning-Aided NOMA Random Access: An AoI-Based Timeliness Perspective
Oct 07, 2024In this paper, we investigate the age-of-information (AoI) of a power domain non-orthogonal multiple access (NOMA) network, where multiple internet-of-things (IoT) devices transmit to a common gateway in a grant-free random fashion. More specifically, we consider a framed setup composed of multiple time slots, and resort to the $Q$-learning algorithm to properly define, in a distributed manner, the time slot and the power level each IoT device transmits within a frame. In the proposed AoI-QL-NOMA scheme, the $Q$-learning reward is adapted with the aim of minimizing the average AoI of the network, while only requiring a single feedback bit per time slot, in a frame basis. Our results show that AoI-QL-NOMA significantly improves the AoI performance compared to some recently proposed schemes, without significantly reducing the network throughput.