 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-loop Reasoning For Traffic Sign Detection: Collaborative Approach Yolo With Video-llava
Oct 07, 2024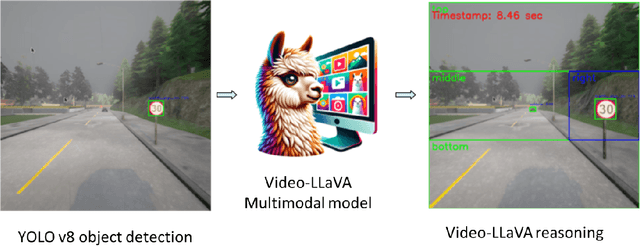

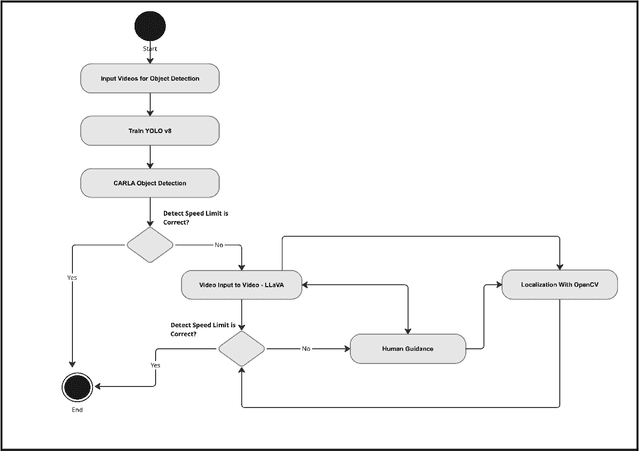

Traffic Sign Recognition (TSR) detection is a crucial component of autonomous vehicles. While You Only Look Once (YOLO) is a popular real-time object detection algorithm, factors like training data quality and adverse weather conditions (e.g., heavy rain) can lead to detection failures. These failures can be particularly dangerous when visual similarities between objects exist, such as mistaking a 30 km/h sign for a higher speed limit sign. This paper proposes a method that combines video analysis and reasoning, prompting with a human-in-the-loop guide large vision model to improve YOLOs accuracy in detecting road speed limit signs, especially in semi-real-world conditions. It is hypothesized that the guided prompting and reasoning abilities of Video-LLava can enhance YOLOs traffic sign detection capabilities. This hypothesis is supported by an evaluation based on human-annotated accuracy metrics within a dataset of recorded videos from the CARLA car simulator. The results demonstrate that a collaborative approach combining YOLO with Video-LLava and reasoning can effectively address challenging situations such as heavy rain and overcast conditions that hinder YOLOs detection capabilities.